

歡迎來到這篇有趣的新程式教學文章!Swift 是種富含多種特性的語言,當中有一個不能錯過的良好特性,就是高階函數 (higher order functions)。根據 Wikipedia 上面的解釋所描述:
在數學和計算機科學中,高階函數是至少滿足下列其中一個條件的函數:
- 接受一個或多個函數作為輸入
- 輸出一個函數所有其他函數皆為一階函數
從現實世界程式設計的實際觀點來看,高階函數是百利而無一害的工具。我們不必實作 Swift 中已有的功能,而且可以透過更少程式碼完成同樣的功能。高階函數通常會應用在集合型別(陣列 (arrays)、字典 (dictionaries)、集合 (sets))上,而如你在下文可見,它們目的就是以不同方式用於所包含的元素中。雖然它們被稱為「函數」,你還是可以透過將要使用的集合物件 (collection object),使用點語法 (dot syntax) 將它們作為方法使用。
如果真要說一個高階函數的缺點,比起其它更「Swifty」的程式碼來說,高階函數的寫法可能會讓人有些不習慣。不過,即使你不適應它們,還是可以選擇這個讓生活更輕鬆的工具,因為這都只是需要時間習慣及訓練而已。如果高階函數的技巧並不在你的程式技能樹規劃裡面,那麼請開始嘗試使用它們,它們將會成為你程式設計日常中的最好工具。
高階函數建基於閉包 (Closure) 上,但是你不一定要精通閉包才能瞭解下一步。然而,如果你需要回顧一下或是瞭解多點關於閉包的資訊,你可以在讀下去之前先看一下 Apple 的官方文件。高階函數之所以令人驚豔,是因為它們可以用非常短的方式來編寫,所以我們可以將平常所寫的五、六行程式碼,以一行的方式來完成。實現這種簡短的編寫方式,就是靠像 $0、$1 的這種速記參數 (Shorthand arguments)(這種用法在剛剛官方文件的連結中也有提到)。我們在接下來的部分就會討論到這一點,所以現在不需要更進一步地討論。
在本次的教學中,我將會介紹 Swift 中最著名、也最常用的高階函數:
- map
- compactMap
- flatMap
- filter
- reduce
- forEach
- contains
- removeAll
- sorted
- split
讀完這篇文章之後,你將會學到所有高階函數的必要概念與技巧,並能夠實際地將它們應用到你的專案之中。所以,讓我們立即開始吧!
在 Swift 中使用高階函數之前的準備工作
與我們平常的教學文章不同,這次我們沒有起始專案作練習之用。為了要順利嘗試本次教學文章的內容,你可以使用建立一個或多個 Xcode 的 playgrounds 來作為本次的開發環境。
在這裡補充一個實用的小技巧,如果你發現 playground 看似被凍結了,不執行你所輸入的程式碼,那麼你可以嘗試:
- 顯示檢閱器 (Inspector) 視窗。
- 在 File 檢閱器中的 Playground Settings 部分,選擇 macOS 為平台。
此外,在開始添加客製化程式碼之前,你可以使用下列程式碼取代任何新 playground 之中的預設程式碼:
import Foundation因為在本次練習中我們並不需要任何 UI,你不需要導入 UIKit 或 Cocoa 框架(視乎你選擇創建 iOS 或 macOS playground)。如果你想知道更多關於 playground 的技巧,只要在網站快速搜尋一下,你就能找到許多有用的資訊。這篇教學文章不會討論關於 playground 的細節,所以我會假設你對 playground 已經有基本的認識,可以在上面執行程式碼。
Map
讓我們開始第一個、又是最有名的高階函數 map 吧!這個函數「會對所有集合型別中的元素執行操作,並回傳含有對原本元素操作結果的新集合」。這聽起來很棒,但實際上它是如何運作的呢?
在 Xcode 創建一個 playground,並加入下列程式碼:
let numbers = [2, 5, 3, 9, 15, 12, 8, 17, 20, 11]這個陣列包含了十個整數,讓我們嘗試創建一個新的陣列,包含上列數字的雙倍數值。如果我們不使用任何高階函數,而使用傳統的 for-in 迴圈來實現的話,就會寫成下列程式碼:
var doubled = [Int]()
for number in numbers {
doubled.append(number * 2)
}
print(doubled)
// Prints [4, 10, 6, 18, 30, 24, 16, 34, 40, 22]首先,我們初始化一個新的陣列,並指定其元素型別。接著,使用迴圈來將每個數字從原本的陣列中變為兩倍,並附加到新創建的陣列之中,最後再把陣列印出來以便我們來確認結果。
現在讓我們來首度嘗試使用 map,並看看如何使用更精簡而聰明的程式碼,來達到同樣的結果。在 playground 中輸入下列程式碼:
doubled = numbers.mapXcode 會自動跳出 map 函數的建議,按下 Return 鍵應該就會獲得這個:

接著再按一次 Return,讓 Xcode 展開佔位符 (placeholder),並提供預設的實作。

首先來看看閉包,我們在當中把想要執行的實作加到原始數據中。它帶有一個參數,而該參數就代表原始集合中的單一元素。在這個範例中,參數就代表著 numbers 陣列中的每個數字。高階函數會在集合上進行迭代,所以參數就依次代表著集合中的所有項目。
接著,還有一個泛型的回傳型別 T,它必須被明確地指定。這是閉包將要回傳的數據型別,在這邊我們將會回傳 Int 數值。
所以,讓我們將參數名稱設定到佔位符之中,並修正閉包的回傳型別:
doubled = numbers.map({ (number) -> Int in
})不要忘記 map 函數會回傳一個新的集合,在這個範例之中,它會回傳一個整數陣列,包含了我們所指派的 doubled 變數。
請注意,保存結果的陣列不需要像之前一樣先初始化,我們可以直接將它刪除:
var doubled = [Int]()並在變數前使用 let 或是 var 關鍵字來保存 map 的結果:
let doubled = numbers.map({ (number) -> Int in
})現在,在閉包的本體之中,我們將會加入需要應用的客製化邏輯,也就是把 number 參數變成雙倍:
let doubled = numbers.map({ (number) -> Int in
return number * 2
})再次將 doubled 陣列印出,我們再次獲得原始數字加倍的結果。太棒了!
上文使用 map 函數的方式是完全正確的,不過實際上我們可以使它變得更短!那要怎麼做?就是不寫出含有參數與回傳型別的完整閉包定義,並善用速記參數來完成:
let doubled = numbers.map { $0 * 2 }$0 是一個速記參數,它是一種通用方式,用來參照原本集合中的任何元素。在這個範例中,它代表的是 numbers 陣列中的任何數字,就像是剛剛範例中 map 的 number 參數。
除此之外,你也可以注意到方法中的左和右括號都被省略。為了提高可讀性,map 關鍵字和大括號之間只有一個可選的空格。
再次將 doubled 陣列印出後,我們可以在除錯區看到這次的結果依然與先前兩次相同。但是這次有一個不同的地方,就是我們只使用了一行程式碼,就將原本數值加倍,並將它們置於新的 doubled 陣列之中。高階函數真的令人驚奇,對吧?
讓我們再來看看另一個範例。看看下列包含角度數值的陣列:
let degrees = [20, 45, 160, 360, 84, 215, 178, 185]我們想要將它們轉換為弧度,同樣可以使用 map 函數以一行程式碼來完成:
let rads = degrees.map { Double($0) * Double.pi / 180.0 }你可以看到處理速記參數 $0 的方式就如同一般參數一樣。雖然金錢符號看起來可能有點怪,但這並不會影響你,這就只是表達模式而已。
如果不使用 Map 函數,我們就需要這樣來做轉換:
var rads = [Double]()
for deg in degrees {
rads.append(Double(deg) * Double.pi / 180.0)
}這個方法也可以,但是使用 map 我們可以使用更少的程式碼完成目的,以提高撰寫程式碼的效率。
Map 與 Dictionaries
除了陣列以外,map 函數還可以應用到其他集合型別,字典以及集合也是集合型別,雖然透過字典來使用的方法會有些不同,這取決於我們想要只獲取鍵 (keys)、或值 (values)、或兩者都獲取。
讓我們宣告一個字典,並填入下列數值:
var info = [String: String]()
info["name"] = "andrew"
info["city"] = "berlin"
info["job"] = "developer"
info["hobby"] = "computer games"將上述字典印出,我們可以獲得:

map 函數會回傳一個含有數值的陣列,所以要單獨獲得鍵或值其實非常容易:
let keys = info.map { $0.key }
let values = info.map { $0.value }info 就是字典,因此要引用鍵和值,就分別需要使用 key 和 value 訪問器 (accessor)。添加以下兩個語句:
print(keys)
print(values)這將會印出接下來的兩行。一如我們預期,這會有兩個含有不同數值的陣列:

但是,如果我們這樣做的話,會發生什麼事呢?
let result = info.map { $0 }
print(result)結果會像這樣:

result 陣列中的每個元素都變成了一個 tuple,當中第一個數值為鍵,而第二個數值為鍵所對應的值。
像上文這樣的陣列,可以以下列程式碼來初始化一個字典:
let newInfo = Dictionary(uniqueKeysWithValues: result)當然,如果我們不修改原始數據就進行上述操作,是沒有任何意義的,這樣子 newInfo 字典會跟 info 完全相同。因此,讓我們先對鍵和值兩者進行操作吧!我們想要實現的,是將鍵轉換為大寫的字串,並將每個值的首字母轉換成大寫。接著,我們將使用經過調整的鍵和值,創建一個新的字典。
如上文所示,我們會在最後創建新字典。但在這之前,讓我們先定義 map 函數,在該函數中我們將回傳具有修改後的鍵和值的客製化元組值 (tuple value):
let updatedKeysAndValues = info.map { ($0.key.uppercased(), $0.value.capitalized) }在兩個大括號之間,那個有兩個數值在內的括號就是元組,兩個數值分別是鍵在前和值在後。我們使用字串類別的 uppercased() 方法,將鍵的值轉換為大寫,再使用 capitalized 屬性(同樣屬於字串類別),來將值的首字母轉換為大寫。
關於上面使用的速記參數,這裡有一個重點。針對 $0.key 和 $0.value,我們可以改寫成:
let updatedKeysAndValues = info.map { ($0.uppercased(), $1.capitalized) }$0 參數參照到鍵,而 $1 參數參照到值。兩種方式都是正確的,你可以選擇你覺得合適的方式。
現在,讓我們來創建一個新的字典:
let capitalizedInfo = Dictionary(uniqueKeysWithValues: updatedKeysAndValues)
print(capitalizedInfo)結果如下:

我們也可以將上面的動作寫成一行程式碼,就像是這樣:
let capitalizedInfo = Dictionary(uniqueKeysWithValues: info.map { ($0.uppercased(), $1.capitalized) } )MapValues – 一種 Map 的變形
看完上述的內容後,讓我們來看看另一種相當簡潔的方式,讓我們獲取保持原始的鍵和修改了的值的字典,那就是不同的高階函數,是 map 的變形,稱為 mapValues:
let updatedInfo = info.mapValues { $0.capitalized }
print(updatedInfo)結果如下:
["job": "Developer", "city": "Berline", "name": "Andrew", "hobby": "Computer Games"]updatedInfo 就是你所看到的字典,因此我們不需要手動創建。如果你不想修改字典的鍵,就可以使用 mapValues 高階函數。如果想同時修改鍵和值,你只需要使用 map 。
Map 與客製化型別
map 函數(一般來說是高階函數)可以用於其元素都是客製化型別實例的集合型別之中。讓我們來看看一個例子,以下類別包含了儲存關於產品測試員資訊的屬性:
class Tester {
var name: String
var age: Int
init(name: String, age: Int) {
self.name = name
self.age = age
}
}讓我們創建一個測試員的陣列:
let testers = [Tester(name: "John", age: 23), Tester(name: "Lucy", age: 25), Tester(name: "Tom", age: 32), Tester(name: "Mike", age: 29), Tester(name: "Hellen", age: 19), Tester(name: "Jim", age: 35)]假設我們現在為了統計,需要從陣列之中去單獨讀取每個測試員的年齡資訊。我們可以透過 map 函數搭配速記參數的方式,很簡單地就完成讀取 age 屬性:
let ages = testers.map { $0.age }
print(ages)結果如下:
[23, 25, 32, 29, 19, 35]在這個範例之中,$0 參數就代表了 Tester 物件,所以我們可以將它視為該類別,來獲取 age 屬性。
CompactMap
compactMap 函數與 map 非常相似,但有個很大的不同,就是它的結果陣列並不會包含任何 nil 值。為了更清楚地說明這一點,讓我們看看下列範例,以下的陣列包含了整數與一些 nil 值:
let numbersWithNil = [5, 15, nil, 3, 9, 12, nil, nil, 17, nil]這個陣列的型別明顯是 [Int?]。現在假設我們想要透過 map 函數,將非空值的元素加倍,並產生出一個新的陣列,做法會像是下面這樣:
let doubledNums = numbersWithNil.map { $0 * 2 }Xcode 會顯示出下列的錯誤訊息:

看到這個錯誤並不意外,因為 $0 參數如果是整數,我們就可以將它加倍,但如果是空值,就沒有數值可以被加倍了。為了解決這個情況,我們必須解開 $0 參數,並在只有非空值的情況之下執行加倍,map 函數的完整寫法如下:
let doubledNums = numbersWithNil.map { (number) -> Int? in
if let number = number {
return number * 2
} else {
return nil
}
}可以看到閉包的回傳型別為 Int?,代表閉包會回傳一個加倍的整數值、或是在 number 參數為 nil 時回傳 nil。根據閉包的回傳型別,可以推論出 doubledNums 陣列的型別也會是 [Int?]。
而上面做法的簡化版本如下:
let doubledNums = numbersWithNil.map { $0 != nil ? $0! * 2 : nil }在這裡,我們使用了三元運算子 (ternary operator) 讓表達更加簡潔。如果 $0 不是空值,我們將會回傳加倍後的整數;而如果 $0 是空值,我們就同樣回傳空值。而 doubledNums 也像剛剛一樣,被推論為同樣的型別。
加入下列 print 指令:
print(doubledNums)我們將會獲得結果:

然而,像上面的結果,擁有可選型態及空值的陣列並不理想。這問題的解決方案就是使用 compactMap 函數,在 numbersWithNil 陣列中使用它,結果的陣列將會只包含非空值的數值,而該陣列的型態會是 [Int]。
這次,讓我們使用 compactMap 來完成剛剛所做的事情:
let notNilDoubled = numbersWithNil.compactMap { $0 != nil ? $0! * 2 : nil }這次的結果如下:
[10, 30, 6, 18, 24, 34]我們可以看到,如果原始陣列中含有空值,結果陣列中元素的數量與原本陣列很明顯是不同的。所以,如果元素數量在你的程式碼中很重要的話,你可能還是得使用 map 函數,以在空值的情形下給予預設值,這樣一來就能保留原本陣列的元素數量。我們可以調整一下剛剛上面的做法,以下的 map 函數同樣會將非空值加倍後回傳,但是在空值的情況之下它會回傳 -1:
let doubledNums = numbersWithNil.map { $0 != nil ? $0! * 2 : -1 }結果就會變成這樣:
[10, 30, -1, 6, 18, 24, -1, -1, 34, -1]在這範例中,-1 回傳值是隨機選的。你在程式碼中做類似操作的時候,請務必特別小心,以防所謂的預設值對程式的整體功能帶來負面、或預計之外的影響。
FlatMap
當集合型別裡面包含另一種集合型別,而我們想要將它們合併成單一集合型別的時候,flatMap 就大派用場了。看看下面的陣列中,它的元素是包含著其他陣列的。假設裡面的陣列每個都包含了三個不同課程的學生成績:
let marks = [[3, 4, 5], [2, 5, 3], [1, 2, 2], [5, 5, 4], [3, 5, 3]]使用傳統的 for-in 迴圈,我們可以獲取單一陣列之中的所有數值:
var allMarks = [Int]()
for marksArray in marks {
allMarks += marksArray
}然而,如果我們使用 flatMap 高階函數,就可以避免這些手動工作:
let allMarks = marks.flatMap { (array) -> [Int] in
return array
}閉包的參數代表在原始集合型別中,應用了高階函數的內層集合型別 (inner collection)。你需要指明結果陣列的型別,在這個範例中,型別就是 [Int]。如果不需要對 array 參數值的元素執行任何操作的話,那麼只需要回傳該陣列即可。
我們也可以進一步透過速記參數來精簡上述的程式碼:
let allMarks = marks.flatMap { $0 }在這樣的情況下,如果我們把所有結果印出,除錯區就出現以下結果:
print(allMarks)
// Prints [3, 4, 5, 2, 5, 3, 1, 2, 2, 5, 5, 4, 3, 5, 3]我們將所有數值放在同一個陣列之中,就可以進一步的執行所需要的操作或運算。
如果內部集合型別包含空值,那麼我們使用 flatMap 函數時,空值也會被帶入到結果陣列之中。你可以看看以下的範例:
let valuesWithNil = [[2, nil, 5], [4, 3, nil], [nil, nil, 1]]
let result = valuesWithNil.flatMap { $0 }
print(result)
// Prints [Optional(2), nil, Optional(5), Optional(4), Optional(3), nil, nil, nil, Optional(1)]Filter
filter 也是其中一個很有用的高階函數。顧名思義,這個函數的目的,是根據某些條件,來過濾集合型別裡的元素,並生成一個僅包含符合條件元素的新集合型別。
為了展示 filter 的使用方式,讓我們再次使用在 map 函數範例中看到的 numbers 陣列:
let numbers = [2, 5, 3, 9, 15, 12, 8, 17, 20, 11]假設我們想要過濾上述陣列,只保留當中大於 10 的元素。如果不使用 filter 函數,我們可以這樣做:
var over10 = [Int]()
for number in numbers {
if number > 10 {
over10.append(number)
}
}接下來,看看我們如何透過 filter 函數來達到同樣的目的:
let over10 = numbers.filter { (number) -> Bool in
if number > 10 {
return true
} else {
return false
}
}我們能夠寫得再簡短一點:
let over10 = numbers.filter { (number) -> Bool in
return number > 10
}你可以注意到,我們不需要明確地指出函數的回傳型別,它總會是 Bool,而我們撰寫在閉包中的程式碼,必須是一個結果是 true/false 的條件。
我們又可以用速記參數,將上面的程式碼變得更簡短:
let over10 = numbers.filter { $0 > 10 }不論上面的哪一種形式,最後都會回傳同樣的結果:
[15, 12, 17, 20, 11]在 filter 之中的條件,可以很簡單,也可以很複雜。而且,就如 map 函數一樣,客製化的物件可以被包含在原始的集合型別之中,並且使用點語法來存取它們的屬性。還記得在 map 函數部分那一個小型的 Tester 類別,和我們初始化了的測試員嗎:
class Tester {
var name: String
var age: Int
init(name: String, age: Int) {
self.name = name
self.age = age
}
}
let testers = [Tester(name: "John", age: 23), Tester(name: "Lucy", age: 25), Tester(name: "Tom", age: 32), Tester(name: "Mike", age: 29), Tester(name: "Hellen", age: 19), Tester(name: "Jim", age: 35)]我們只需要利用一個 filter 函數,就可以找到名字以 “J” 開頭、而年齡大於三十歲的測試員:
let results = testers.filter { $0.name.prefix(1) == "J" && $0.age >= 30 }在這個範例中,我們知道有一個符合條件的測試員,所以可以放心地將結果印出:
print(results[0].name, results[0].age)結果如下:
Jim 35然而,在實際應用時,我們應該先這樣確認一下結果是否存在:
if results.count > 0 {
// Do something...
}通常在過濾出所需要的結果之後,我們必須取得集合型別中的第一個項目。舉例來說,要取得第一個名字以 “J” 開頭的測試員,比較常見但不太精簡的方式是:
let filtered = testers.filter { $0.name.prefix(1) == "J" }
if filtered.count > 0 {
let firstTester = filtered[0]
// Do something with firstTester...
}如果不使用索引值的方法,另一個方法是可以使用 first 屬性來獲得 filtered 陣列中的第一個項目。但這裡要注意一點,因為回傳的值有可能是空值,所以必須要做拆解的動作。
let filtered = testers.filter { $0.name.prefix(1) == "J" }
if filtered.count > 0 {
if let firstTester = filtered.first {
// Do something with firstTester...
}
}雖然上面的程式碼是正確的,我們可以使用 guard 來簡化程式碼:
guard let firstTester = (testers.filter { $0.name.prefix(1) == "J" }).first else { return }
// Do something with firstTester...我們也可以使用類似的方式,來計數集合型別中被過濾後的項目。在範例的 numbers 陣列中,我們可以計算有多少個大於十的數值:
let totalOver10 = numbers.filter { $0 > 10 }.count
print("Total items greater than 10: ", totalOver10)結果如下:
Total items greater than 10: 5關於 filter 函數,還有一個重點:它並沒有對集合型別中的元素做任何修改(像是 map 就有)。我們使用 filter 只是為了獲取原始數據中,滿足特定條件的子集合。假如你想要對過濾後的數據做進一步的操作,你可以使用 filter 函數所產生出結果,作為其他高階函數所使用的輸入數據。
Reduce
reduce 高階函數的目的,是為了從原本集合型別中的所有元素來產生一個值。為了解這個函數的用法,假設我們想要計算下列陣列中所有元素的乘積 (product):
let numbers = [5, 3, 8, 4, 2]若不使用 reduce 函數,而是用 for-in 迴圈來實作的話,將每個數值乘起來所獲得的結果應該像是這樣:
var product = 1
for number in numbers {
product *= number
}然而,不同於上面的做法,使用 reduce 函數也能夠獲得同樣的結果。正如同你等一下看到的程式碼中,它會接收兩個參數,第一個是初始值(就像是剛剛的 product 變數),而第二個是閉包中所需要實作在集合型別裡元素的邏輯。
let product = numbers.reduce(1) { (partialResult, number) -> Int in
return partialResult * number
}這個閉包的參數也是非常有趣的,因為第一個參數並不像第二個參數一樣,代表著集合型別中的元素,第一個參數是代表先前用來與 number 數值相乘的結果。讓我再清楚一點來說明:
// 1st iteration: partialResult = 1, number = 5, Returns 5
// 2nd iteration: partialResult = 5, number = 3, Returns 15
// 3rd iteration: partialResult = 15, number = 8, Returns 120
// 4th iteration: partialResult = 120, number = 4, Returns 480
// 5th iteration: partialResult = 480, number = 2, Returns 960reduce 也可以使用速記參數來簡化:
let product = numbers.reduce(1, { $0 * $1 })別忘記第一個參數都是代表上一個運算結果,而不是集合型別中的元素。在這裡,$0 就代表上一個運算結果,而 $1 就代表著陣列中的元素。
像我們範例這麼簡單的情況中,reduce 還可以用再進一步簡化,甚至可以連速記參數的部分都省略掉。我們唯一所需要的,就是要執行的操作符號:
let product = numbers.reduce(1, *)使用這語法時要小心,請確認你的初始值是正確的。
reduce 也可以搭配字典使用。看看下列字典,包含了五個朋友、以及他們各自擁有的零用錢:
let friendsAndMoney = ["Alex": 150.00, "Tim": 62.50, "Alice": 79.80, "Jane": 102.00, "Bob": 94.20]他們想知道所擁有的金錢總額是否足夠,讓他們一起購買非常想要的新遊戲機。使用 reduce 函數,只要一行程式碼就能夠完成:
let allMoney = friendsAndMoney.reduce(0, { $0 + $1.value })你可以看到上面這行程式碼有趣的地方:為了在閉包中獲取所有的金錢數值,我們必須使用 value 屬性,因為 $1 並不是一個單一數值,它其實是一個 (String, Double) 鍵值對 (key-value pair)(元組)。而另一方面,$0 就是用來代表先前運算結果的單一數值。
ForEach
對於開發者來說,大家都非常瞭解如何撰寫 for-in 迴圈來遍歷集合型別之中的所有元素。從以下的例子中,你可以看到我們如何遍歷 numbers 陣列中的所有元素,並且印出每個元素是奇數或是偶數。
let numbers = [2, 5, 3, 9, 15, 12, 8, 17, 20, 11]
for number in numbers {
number.isMultiple(of: 2) ? print("\(number) is even") : print("\(number) is odd")
}結果如下:
2 is even
5 is odd
3 is odd
9 is odd
15 is odd
12 is even
8 is even
17 is odd
20 is even
11 is odd上述的迴圈可以使用 forEach 函數來取代。就如其他高階函數一樣,forEach也提供了閉包來實作所需要的自定義邏輯。讓我們使用 forEach 函數來再次實現上面所做的事情吧:
numbers.forEach { (number) in
number.isMultiple(of: 2) ? print("\(number) is even") : print("\(number) is odd")
}我們也可以搭配速記參數,只使用一行程式碼來完成:
numbers.forEach { $0.isMultiple(of: 2) ? print("\($0) is even") : print("\($0) is odd") }我們經常會遇到的情況是,我們需要在迴圈內部有條件地解開可選型態來獲取數值,因此需要分別使用 break 與 continue 語句,來中斷或是繼續迴圈的執行。看看以下的範例:
let numbersWithNil = [5, 15, nil, 3, 9, 12, nil, nil, 17, nil]
for number in numbersWithNil {
guard let number = number else {
print("Found nil")
continue
}
print("The double of \(number) is \(number * 2)")
}在上述程式碼之中,continue 語句是用來辨別程式是否要進行到下一個迭代 (iteration),以防在 guard 拆解 number 內容時遇到失敗的情形(在 else 情況下執行所有操作後)。我們不可能在 forEach 函數之中做到一樣的事情,因為 continue 及 break 語句並不能在這裡使用。反之,return 是唯一能夠使用的語法。使用它的時候,程式會離開當前的閉包,不過如果集合之中有更多的元素,通常會隨即使用 forEach 函數。讓我們直接看看程式碼的實作:
numbersWithNil.forEach { (number) in
guard let number = number else {
print("Found nil")
return
}
print("The double of \(number) is \(number * 2)")
}簡而言之,請記住 continue 及 break 語法並不能在 forEach 函數之中使用;它們只能夠在迴圈當中使用,而 forEach 函數並不是迴圈。
Contains
contains 函數是用於集合型別中,以確認當中有沒有能滿足特定條件的元素,而它會回傳一個布林值 (boolean value)。假設我們現在想找找 numbers 陣列之中,是否有包含小於 5 的元素。如果我們利用迴圈來實作,方法應該是這樣:
var containsLessThan5 = false
for number in numbers {
if number < 5 {
containsLessThan5 = true
break
}
}不過,像這樣不斷重複不同的條件、在不同的集合型別上的方式,其實非常沒有效率,也不是一種好的做法。
解決方法就是使用 contains 高階函數!讓我們使用 contains 再次檢查 numbers 陣列之中是否有小於 5 的元素:
let hasNumbersLessThan5 = numbers.contains { (number) -> Bool in
return number < 5
}
print("Has small numbers? :", hasNumbersLessThan5)
// Prints true這個函數不會回傳一個新的集合型別,而是回傳一個布林值,如果結果為 true 就代表條件有被滿足;反之如果結果為 false,就代表條件沒有被滿足。如果條件像上面範例中那樣簡單,我們同樣可以使用速記參數來簡化為一行程式碼:
let hasNumbersLessThan5 = numbers.contains { $0 < 5 }就如同其他高階函數一樣,我們同樣可以在這個函數中使用客製化型別的物件,並且將條件建基於客製化屬性上。看看下面的類別,它包含了一些公司員工的資訊,以及在陣列中的一些實例:
class Staff {
enum Gender {
case male, female
}
var name: String
var gender: Gender
var age: Int
init(name: String, gender: Gender, age: Int) {
self.name = name
self.gender = gender
self.age = age
}
}
let staff = [Staff(name: "Nick", gender: .male, age: 37), Staff(name: "Julia", gender: .female, age: 29), Staff(name: "Tom", gender: .male, age: 41), Staff(name: "Tony", gender: .male, age: 45), Staff(name: "Emily", gender: .female, age: 42), Staff(name: "Irene", gender: .female, age: 30)]我們使用 contains(where:),就能像下面這樣簡單地進行搜尋:
let hasStaffOver40 = staff.contains { $0.age > 40 }
print("hasStaffOver40", hasStaffOver40)
// Prints true
let hasMalesOver40 = staff.contains { $0.gender == .male && $0.age > 40 }
print("hasMalesOver40", hasMalesOver40)
// Prints true
let hasMalesUnder30 = staff.contains { $0.gender == .male && $0.age < 30 }
print("hasMalesUnder30", hasMalesUnder30)
// Prints falsecontains 同樣也可以在字典當中使用,以搜尋是否有符合特定條件的元素。看看下面的字典,包含了幾個城市的攝氏溫度:
let temperatures = ["London": 7, "Athens": 14, "New York": 15, "Cairo": 19, "Sydney": 28]假設高於 25 度就屬於高溫,如果我們想要知道有沒有城市屬於高溫,可以這樣得到答案:
let hasHighTemperatures = temperatures.contains { $0.value > 25 }
print(hasHighTemperatures)
// Prints trueRemoveAll
removeAll 與 contains 函數相似,它可以幫你從原本的集合型別中根據條件刪除元素。在這種情況下,不論是利用 remove(at:) 方法來獲取元素在集合中的索引、或是任何其他的 remove 方法都沒有用。
我們再次使用 numbers 陣列作為範例,不過這次我們使用 var 關鍵字來宣告它,以便後續可以對它做修改:
var numbers = [2, 5, 3, 9, 15, 12, 8, 17, 20, 11]在這邊,我們的目的是移除所有小於 10 的元素:
numbers.removeAll { (number) -> Bool in
return number < 10
}如你所見,沒有任何東西被回傳,不過原本的陣列已經被修改:
print(numbers)結果如下:
[15, 12, 17, 20, 11]上面的方式同樣可以修改為一行:
numbers.removeAll { $0 < 10 }請注意,removeAll 函數只能在陣列中被使用,在字典或是集合中都無法使用。
Sorted
在 Swift 中使用 sorted() 方法,我們可以簡單地將集合中的元素以升序方式排序。看看以下的範例:
let toSort = [5, 3, 8, 2, 10]
let sorted = toSort.sorted()
print(sorted)
// Prints [2, 3, 5, 8, 10]然而,當我們必須要指定排序順序(升序或是降序),或是排序必須基於某個特定條件時,sorted 高階函數可以大派用場了。它可以以三種不同的方式來撰寫,最冗長的形式是這樣:
let sorted = toSort.sorted { (num1, num2) -> Bool in
return num1 > num2
}這兩個參數代表了陣列在排序過程中相互比較的任意兩個元素,閉包會回傳一個布林值,代表定義的條件是否成立。最後,出現了一個新集合型別,當中包含原本集合型別中的元素,但是以特定排序條件所產生的排序結果。剛剛的程式碼會把 toSort 陣列以降序的方式來排序。
我們可以一行程式碼來呈現:
let sorted = toSort.sorted { $0 > $1 }我們會獲得同樣以降序方式來排序的結果陣列,$0 與 $1 參數代表了兩個在排序過程中互相比較的數字。
當然,還有更精簡的方式可以來完成排序:
let sorted = toSort.sorted(by: >)簡單地寫出大於或小於符號已經足夠表示排序順序,請注意,在這個情況中,by 參數名稱不能被省略。
sorted() 方法在字典中也可以使用,然而排序的結果並不是字典的型態,而是元組的陣列,其中元組的第一個元素代表著字典的鍵,而第二個元素代表字典的值。
還記得前文包含溫度資訊的字典嗎?以下我們將使用城市及溫度的資訊,把它們從高溫到低溫排序:
let sortedTemperatures = temperatures.sorted { $0.value > $1.value }以下是將上述結果印在除錯區的樣子:

只要取得陣列有效索引值中特定的元組,就可以獲取任何相應的鍵或是值。舉例來說,我們可以這樣得到第三個城市 (New York) 的溫度資訊:
print(sortedTemperatures[2].value)
// Prints 15我們可以使用 sortedTemperatures 陣列來初始化一個實際的字典。不過鍵和值會再次變成隨機、沒有排序的情況:
let sortedTemperaturesDict = Dictionary(uniqueKeysWithValues: sortedTemperatures)
print(sortedTemperaturesDict)
// Prints ["Cairo": 19, "London": 7, "New York": 15, "Athens": 14, "Sydney": 28]
// By running again it prints ["Cairo": 19, "Athens": 14, "London": 7, "Sydney": 28, "New York": 15]我們也可以用鍵的值來排序字典,以下我們要求城市按字母順序來排序的情況:
let sortedCities = temperatures.sorted { $0.key < $1.key }結果如下:
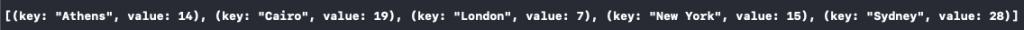
上面的狀況是合乎情理的,因為鍵本身是字串型別,而字串型別遵從 Comparable 協定。
Split
split 函數通常是配合字串來使用的,目的是將字串依照特定條件拆解為片段,最後的結果會是一個由子字串所組成的陣列。它有點像是 components(separatedBy:),都是透過特定分隔字元來將字串拆解。請注意,在 split 函數中,我們只可以使用字元來作為分隔符號。你可能會問:為甚麼這個函數是用在字串,而不是其他的集合型別上,事實上,split 是用於字串中的字元序列,遵循 Collection 協定。
首先,來看一下 split 是如何宣告的:
func split(maxSplits: Int = Int.max, omittingEmptySubsequences: Bool = true, whereSeparator isSeparator: (Character) throws -> Bool) rethrows -> [Substring]如你所見,它需要三個參數,前面兩個是可選的,適用在有初始值的情況,我們等一下會討論到這一點。而最後一個參數是閉包,用來明確指定原始字串要如何拆解的條件。用一個簡單的範例來說明,讓我們把以下的字串以空格字元來拆解:
let message = "Hello World!"
let result = message.split { (char) -> Bool in
return char == " "
}
print(result)
// Prints ["Hello", "World!"]像是其他高階函數一樣,我們可以使用速記參數將 split 改寫成一行程式碼:
let result = message.split { $0 == " " }現在,假如我們在呼叫 split 時加入了 maxSplits 參數,我們就可以指定字串要按分隔字符拆問多少次;換句話說,會有多少個子字串會從原本字串中創建出來,下列的範例可以更清楚地說明:
let anotherMessage = "This message is going to be broken in pieces!"
let splitOnce = anotherMessage.split(maxSplits: 1, whereSeparator: { $0 == " " })
print(splitOnce)
// Prints ["This", "message is going to be broken in pieces!"]你會發現儘管字串中包含了超過一個空格,但最後還是只拆解了第一個空格的位置,因為我們透過 maxSplits 參數限定了最多只能有一次的拆解動作。
關於 omittingEmptySubsequences 參數,如果將它設為 false,則所有被拆解條件所拆解出來的空子字串,都會出現在結果陣列之中。讓我們修改一下剛剛的字串:
let anotherMessage = "This message is going to be broken in pieces!"現在將 omittingEmptySubsequences 參數的值設為 false,讓我們再次拆解它:
let emptySequences = anotherMessage.split(omittingEmptySubsequences: false, whereSeparator: { $0 == " " })
print(emptySequences)
// Prints ["This", "message", "is", "going", "to", "", "", "", "be", "broken", "in", "pieces!"]最後,還有兩件事要注意的。首先,split 所產生出在陣列中的元素型別是 String.SubSequence,而不是 String。如果你想要把它們當作字串來使用,你必須先使用它們來創建字串物件。下列範例創建了一個新的陣列,而其中所有子字串都透過 map 函數轉型成為字串:
let message = "Hello World!"
let result = message.split { $0 == " " }
print(result)
// Prints ["Hello", "World!"]
// result type is [String.SubSequence]
// Create String values from substrings.
let allStrings = result.map { String($0) }
print(allStrings)
// Prints ["Hello", "World!"]
// allStrings type is [String]第二個注意事項是,你為拆解字串所指定的條件,可以設定得比我們的範例更複雜。下面的範例中,我們以句號及驚嘆號將一段文章拆解為句子。你可以看看 split 函數中的條件:
let paragraph = "This paragraph will be separated in parts. Based on the periods and the exclamation mark! There will be three strings!"
let sentences = paragraph.split { $0 == "." || $0 == "!" }
print(sentences)
// Prints ["This paragraph will be separated in parts", " Based on the periods and the exclamation mark", " There will be three strings"]總結
在這篇文章中,我們透過簡單的範例展示了如何在 Swift 中使用常見的高階函數。我相信大家都注意到,使用高階函數可以減少我們所需要的程式碼,同時,程式碼本身也變得更加清晰及有效率。如果你還沒有在程式碼中使用過高階函數,現在應該考慮開始使用了,因為它們確實帶來很大的幫助。無論如何,我們已經來到本次教學文章的尾聲,希望你今天學到了一些新知識,並為你的程式設計日常帶來莫大的效益!
LinkedIn: https://www.linkedin.com/in/hengjiewang/
Facebook: https://www.facebook.com/hengjie.wang
原文:Understanding Higher Order Functions in Swift