之前,我們簡要介紹了 Google Gemini APIs,並展示了如何使用 SwiftUI 建立一個問答應用程式。你應該體會到將 Google Gemini 整合並藉由 AI 功能增強你的應用程式有多麼直接。我們也開發了一個示範應用程式,來展示如何使用 AI APIs 建立一個聊天機器人應用程式。
在過去的教學中討論過的 gemini-pro 模型僅限於從基於文字的輸入生成文字。然而,Google Gemini 也提供了一個名為 gemini-pro-vision 的多模態模型,該模型可以從圖像生成文字描述。換句話說,這個模型具有檢測和描述圖像中物體的能力。
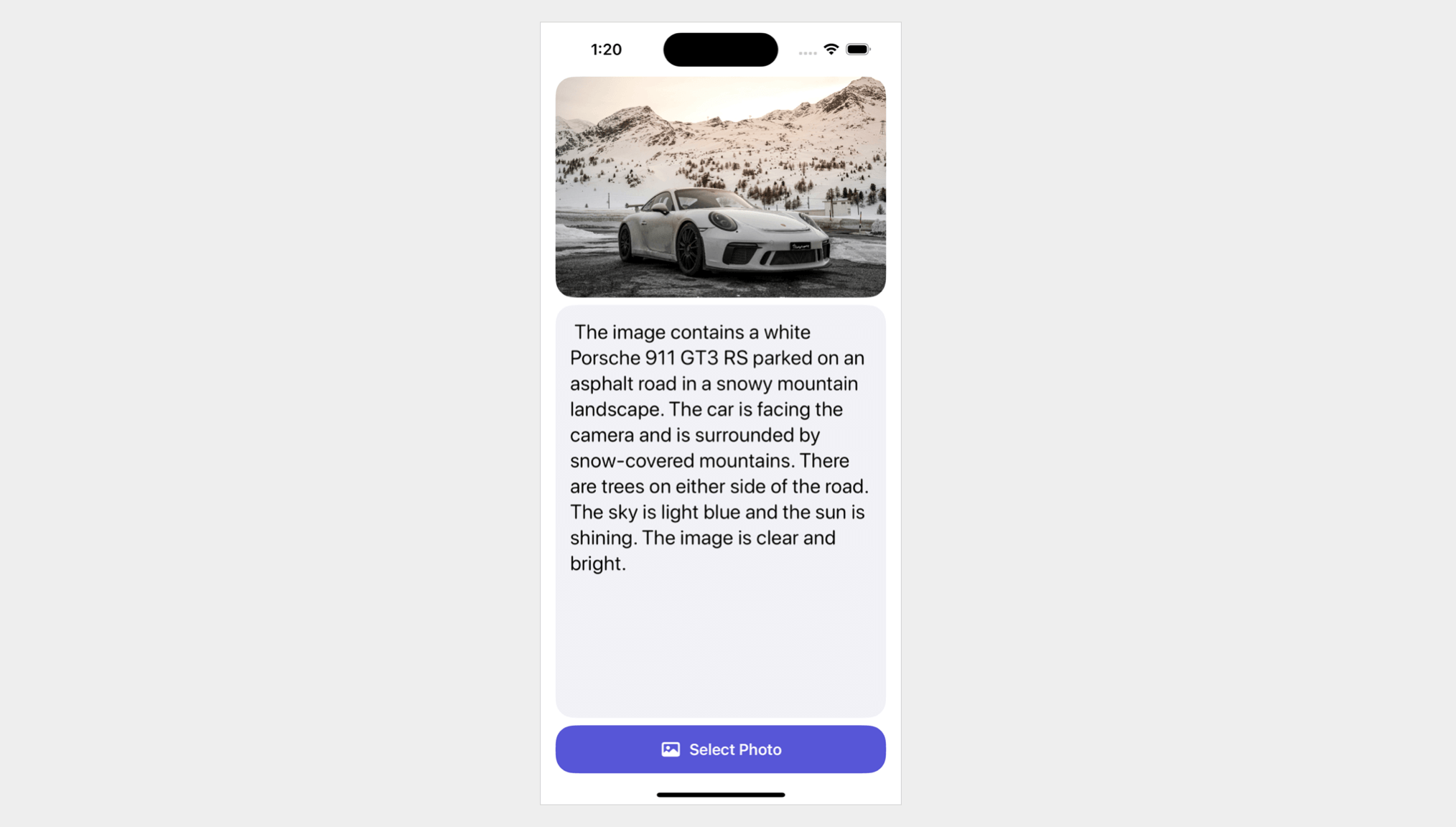
在這個教學中,我們將展示如何使用 Google Gemini APIs 進行影像識別。這個簡單的應用程式允許用戶從照片庫中選擇一張圖片,並使用 Gemini 來描述該照片的內容。
在進行這個教學之前,如果你還沒有的話,請訪問 Google AI 工作室 並創建你自己的 API 金鑰。
在 Xcode 專案中增加 Google Generative AI 套件
假設你已經在 Xcode 中創建了一個應用程式專案,使用 Gemini APIs 的第一步是匯入開發套件。為了完成這個步驟,請在專案導覽器中的專案資料夾上點擊滑鼠右鍵,然後選擇 增加套件依賴。在對話框裡,輸入以下套件網址:
https://github.com/google/generative-ai-swift
然後你可以點擊 增加套件 按鈕來下載並將 GoogleGenerativeAI 套件融合進專案中。
接著,為了存儲 API 金鑰,建立一個名為 GeneratedAI-Info.plist 的屬性文件。在此文件中,建立名為 API_KEY 的鍵,並將你的 API 金鑰輸入為數值。
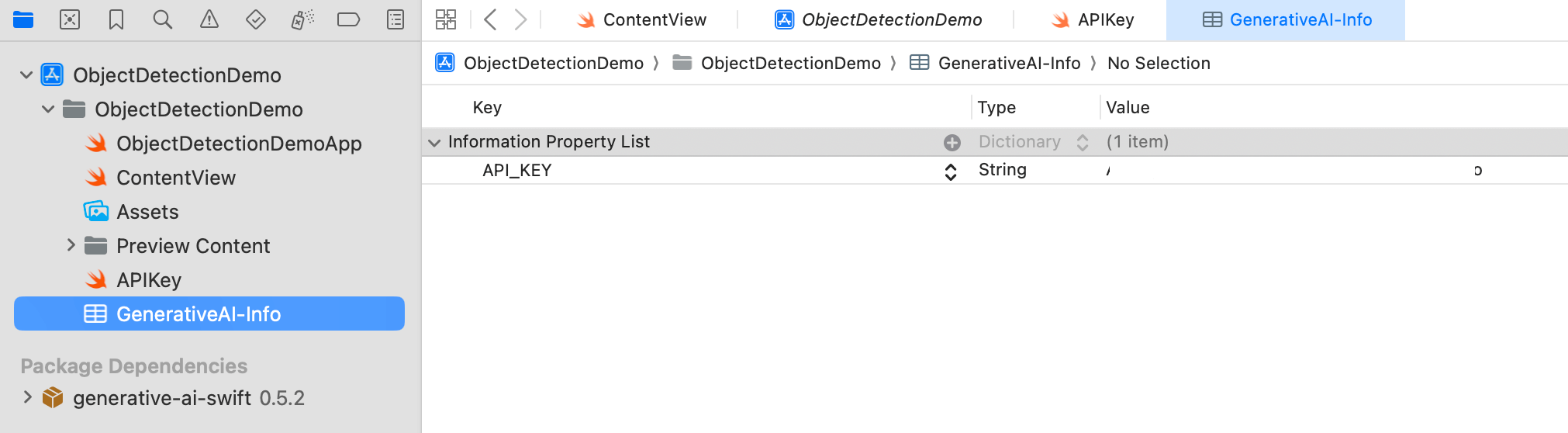
為了從屬性文件讀取 API 金鑰,創建另一個名為 APIKey.swift 的 Swift 文件。將以下程式碼添加到此文件中:
enum APIKey {
// Fetch the API key from `GenerativeAI-Info.plist`
static var `default`: String {
guard let filePath = Bundle.main.path(forResource: "GenerativeAI-Info", ofType: "plist")
else {
fatalError("Couldn't find file 'GenerativeAI-Info.plist'.")
}
let plist = NSDictionary(contentsOfFile: filePath)
guard let value = plist?.object(forKey: "API_KEY") as? String else {
fatalError("Couldn't find key 'API_KEY' in 'GenerativeAI-Info.plist'.")
}
if value.starts(with: "_") {
fatalError(
"Follow the instructions at https://ai.google.dev/tutorials/setup to get an API key."
)
}
return value
}
}建立應用程式的使用者介面

使用者介面直觀易懂。它在融合了一個按鈕在螢幕底部,允許用戶訪問內建的照片庫。一旦選擇了一張照片,它就會出現在圖像視圖中。
為了打開內建的照片庫,我們使用 PhotosPicker,這是一個用於管理照片選擇的原生照片選擇器視圖。當展示 PhotosPicker 視圖時,它會在一張單獨的表單上展示照片庫,並在你的應用程式的界面上完成渲染。
首先,你需要匯入 PhotosUI 框架以便使用照片選擇器視圖:
import PhotosUI接下來,像這樣更新 ContentView 結構來實現使用者介面:
struct ContentView: View {
@State private var selectedItem: PhotosPickerItem?
@State private var selectedImage: Image?
var body: some View {
VStack {
if let selectedImage {
selectedImage
.resizable()
.scaledToFit()
.clipShape(RoundedRectangle(cornerRadius: 20.0))
} else {
Image(systemName: "photo")
.imageScale(.large)
.foregroundStyle(.gray)
.frame(maxWidth: .infinity, maxHeight: .infinity)
.background(Color(.systemGray6))
.clipShape(RoundedRectangle(cornerRadius: 20.0))
}
Spacer()
PhotosPicker(selection: $selectedItem, matching: .images) {
Label("Select Photo", systemImage: "photo")
.frame(maxWidth: .infinity)
.bold()
.padding()
.foregroundStyle(.white)
.background(.indigo)
.clipShape(RoundedRectangle(cornerRadius: 20.0))
}
}
.padding(.horizontal)
.onChange(of: selectedItem) { oldItem, newItem in
Task {
if let image = try? await newItem?.loadTransferable(type: Image.self) {
selectedImage = image
}
}
}
}
}為了使用 PhotosPicker 視圖,我們宣告一個狀態變數來存放照片選擇,然後通過將綁定傳遞給狀態變數來實例化一個 PhotosPicker 視圖。matching 參數允許你指定要顯示的資源類型。
當選擇一張照片後,照片挑選器會自動關閉,將選擇的照片儲存到型別為 PhotosPickerItem 的 selectedItem變數中。loadTransferable(type:completionHandler:) 方法可以用來加載圖像。通過附加 onChange 修改器,你可以監控 selectedItem 變數的更新。如果有變化,我們調用 loadTransferable 方法來加載資源數據,並將圖像保存到 selectedImage 變数。
由於 selectedImage 是狀態變數,所以 SwiftUI 會自動檢測其內容的變化並在融合上顯示圖像。
圖像分析與物體辨識
選擇了圖像後,下一步是使用 Gemini API 執行圖像分析並從圖像生成文本說明。
在使用 API 之前,將以下語句插入 ContentView.swift的開始之處,以匯入框架:
import GoogleGenerativeAI接下來,宣告一個 model 屬性來存放 AI 模型:
let model = GenerativeModel(name: "gemini-pro-vision", apiKey: APIKey.default)對於圖像分析,我們利用 Google Gemini 提供的 gemini-pro-vision 模型。然後,我們宣告兩個狀態變數:一個用於存儲生成的文本,另一個用於追蹤分析狀態。
@State private var analyzedResult: String?
@State private var isAnalyzing: Bool = false接下來,創建一個名為 analyze() 的新功能來執行圖像分析:
@MainActor func analyze() {
self.analyzedResult = nil
self.isAnalyzing.toggle()
// Convert Image to UIImage
let imageRenderer = ImageRenderer(content: selectedImage)
imageRenderer.scale = 1.0
guard let uiImage = imageRenderer.uiImage else {
return
}
let prompt = "Describe the image and explain what the objects found in the image"
Task {
do {
let response = try await model.generateContent(prompt, uiImage)
if let text = response.text {
print("Response: \(text)")
self.analyzedResult = text
self.isAnalyzing.toggle()
}
} catch {
print(error.localizedDescription)
}
}
}在使用模型的 API 之前,我們需要將圖像視圖轉換為 UIImage。然後我們調用 generateContent 方法,並帶上圖像和一個預定義的提示,要求 Google Gemini 描述圖像並識別其中的對象。
當回應到達時,我們提取文本描述並將其分配給 analyzedResult 變數。
接下來,插入以下程式碼並將其放置在 Spacer() 視圖之上:
ScrollView {
Text(analyzedResult ?? (isAnalyzing ? "Analyzing..." : "Select a photo to get started"))
.font(.system(.title2, design: .rounded))
}
.padding()
.frame(maxWidth: .infinity, maxHeight: .infinity, alignment: .leading)
.background(Color(.systemGray6))
.clipShape(RoundedRectangle(cornerRadius: 20.0))這個滾動視圖顯示了 Gemini 生成的文字。您也可以選擇性地在 selectedImage 視圖添加一個 overlay 修飾符。這將在進行圖像分析時顯示進度視圖。
.overlay {
if isAnalyzing {
RoundedRectangle(cornerRadius: 20.0)
.fill(.black)
.opacity(0.5)
ProgressView()
.tint(.white)
}
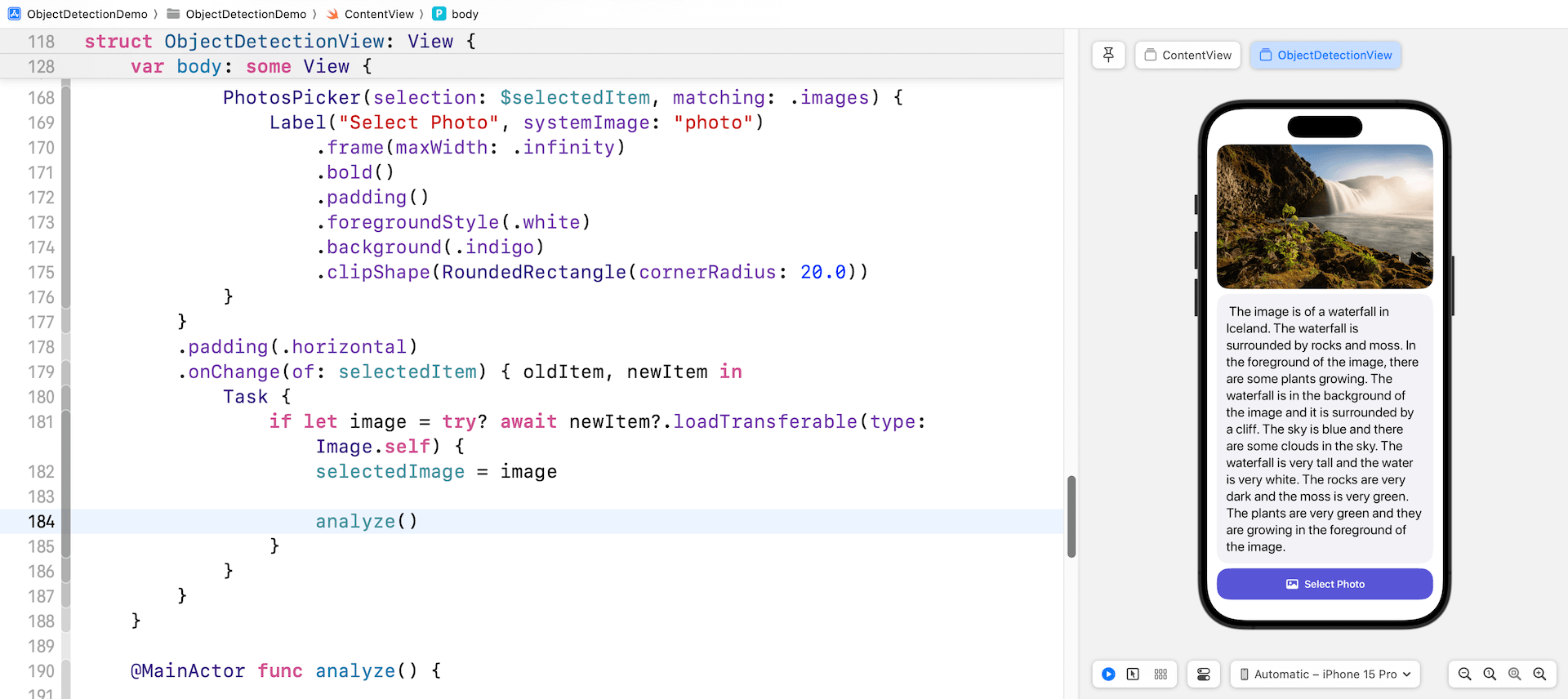
}在實施所有更改後,預覽窗格應該現在顯示新設計的用戶界面。這個界面包括選定的圖像,圖像描述區域,以及從照片庫中選擇照片的按鈕。如果所有步驟都已正確地遵循和執行,這就是您應該在預覽窗格中看到的。
最後,在 onChange 修飾詞中插入一行程式碼,以便在 selectedImage 之後調用 analyze() 方法。就這樣!現在可以在預覽窗格中測試應用程序了。點擊 選擇照片 按鈕並從庫中選擇一張照片。然後,應用程序將會將選定的照片發送到 Google Gemini 進行分析,並在滾動視圖中顯示生成的文字。
總結
本教程演示了如何使用 Google Gemini APIs 和 SwiftUI 構建一個 AI 圖像識別應用程序。應用程序允許用戶從他們的照片庫中選擇一張圖片,並使用 Gemini 來描述照片的內容。
從我們剛剛操作的程式碼中,你可以看到只需要幾行程式碼就可以提示 Google Gemini 從圖像生成文本。雖然這個演示使用一張圖像來描繪過程,但實際上 API 支持多張圖像。有關其功能的更多詳細資訊,請參閱 官方文件。