

歡迎來到新一篇教學,這次我們要來討論兩個有趣而且互相關聯的概念:如何掃描圖片並辨識當中的文字。這件事聽起來或許非常複雜,不過很快你就會發現完全不是如此。有了 Vision 框架,現在要執行文字掃描和辨識,已經是相當簡便的工作了。
讓我們來了解一下文字掃描和辨識的細節。我們會使用 VisionKit 框架,它有一個專用的類別 VNDocumentCameraViewController,來讓裝置可以掃描圖片。這是 UIKit 的視圖控制器 (view controller),讓使用者可以透過系統的介面和相機,來掃描單張或是多張頁面,掃描後我們會得到一些圖片(UIImage 物件),讓我們可以隨意做後續處理。
有了這些掃描取得的頁面,意味著我們得到了包含著文字的圖片,而 Vision 框架 這時候就可以大派用場了。它會以掃描所得的圖片為輸入 (input),然後執行辨識的操作來獲得文字。另外,它也可以為辨識的工作進行一些設定,以便提高辨識的準確度和速度。我們會在文章後面的部分再詳細討論這些細節。
我們會實作一個簡單的 SwiftUI App,來了解本篇文章要介紹的功能。我們會混合應用 UIKit 及 SwiftUI,因為 VNDocumentCameraViewController 是一個 UIKit 的視圖控制器,不過我們會一步一步慢慢地實作,將其他的類別組合起來。
在下一個部分中,我們會概略看一下這篇文章的範例 App,並實作上述提到的所以東西,從掃描文件、到文字辨識的部分。在讀完這篇教學後,你將學會如何整合文字掃描和辨識的功能到你的 App 上。
範例 App 概覽
今天我們會透個一個 SwiftUI App,來探索文字掃描及辨識這個領域。為了節省時間,在開始之前請先先下載起始專案。App 的某些部分已經事先建立好了,但是其他部分還是需要由我們親手打造。
我們的範例是一個導航 App,建基於一個主視圖和一個詳細視圖。ContentView 是主視圖,當中有一個 NavigationView,包含了一個列表和一個在導航列、讓我們啟動掃描的按鈕。你會發現列表視圖預設是無法使用的,因為有一部分程式碼的實作還沒有存在。也就是說,在這個起始專案中我們還未能導航;我們必須加上那些尚未存在的部分,才能使用導航功能。
我們的範例 App 完成後會是這樣:
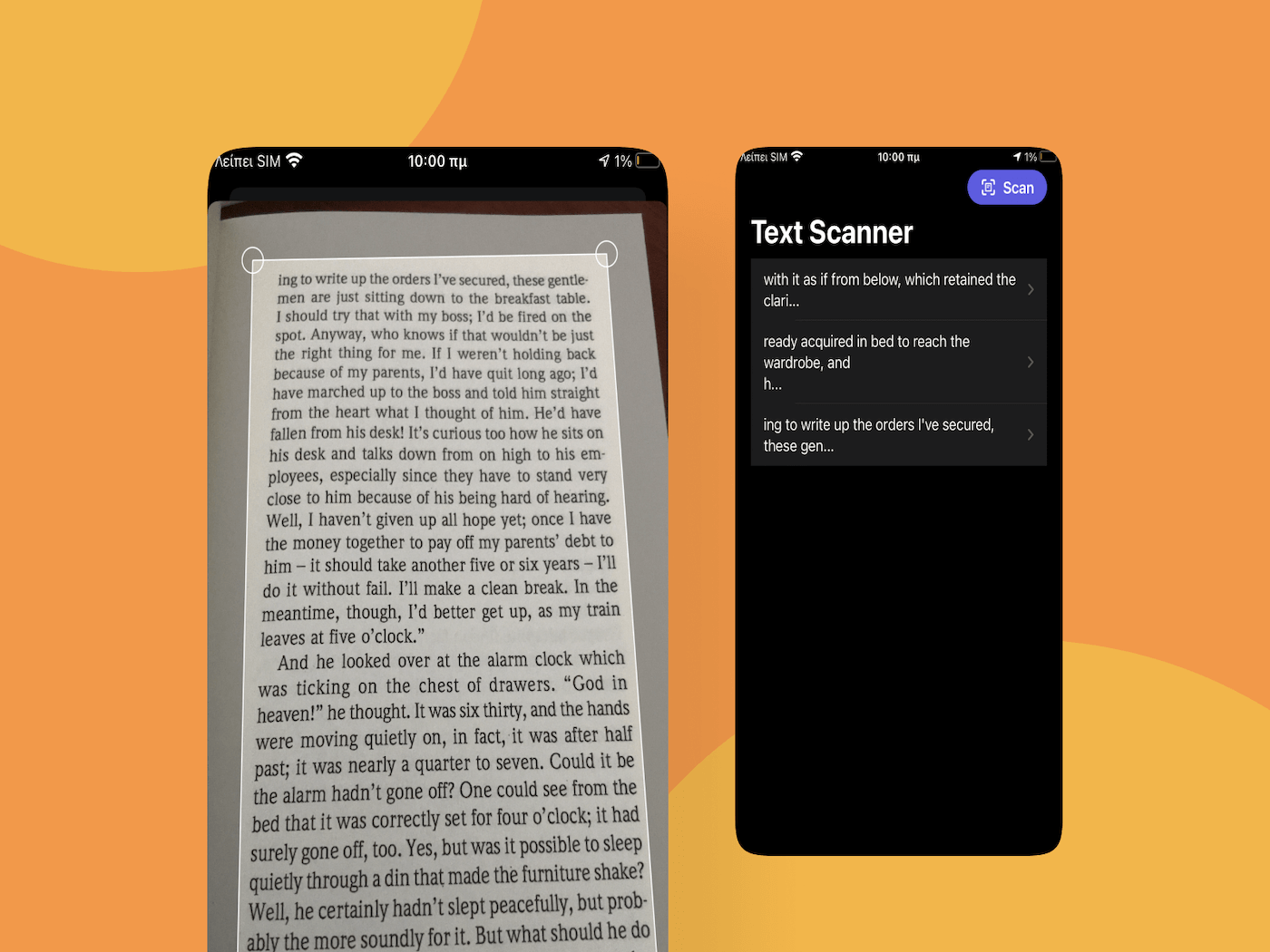
點擊 Scan 按鈕之後,App 會展示一個系統提供的控制器,用來掃描圖片。掃描之後,所有圖片會被傳送到我們將會實作的文字辨識功能中,並且開始進行辨識。經過辨識之後,從圖片中辨識出來的文字會被顯示在列表之中,而我們點擊列表中的物件,就可以在第二個視圖 TextPreviewView 中預覽完整的文字。
在進行這個教學的下一步之前,我們首先需要建立幾個檔案來添加新的程式碼,並對原本已存在於起始專案裡的 SwiftUI 視圖來做一些修改。下載了範例 App 之後,就來看看如何顯示一個掃描視圖吧!
請註意:要使用相機來掃描文字,我們先要先取得使用者的權限。因此我們必須在 Info.plist 檔案內加上一個參數 NSCameraUsageDescription,或是更口語化一點的名稱 Privacy – Camera Usage Description。這個參數和使用相機的原因都已經包含在起始專案中。不過請謹記,如果沒有這個參數的話,在使用相機時 App 就會崩潰 (Crash)。
實作掃瞄器
讓我們開始實作掃描控制器吧!首先,我們要在專案中加入一個新的檔案。在鍵盤按下 Cmd+N,並在跳出的視窗中選擇 Swift File 模版。下一步,將這個檔案命名為 ScannerView 就可以了。
如果前文的簡介中提到,VNDocumentCameraViewController 是一個 UIKit 的視圖控制器。為了要讓這個檔案可以在 SwiftUI 中使用,我們需要實作一個客製化結構 (structure) 來遵從 UIViewControllerPresentable 協定。在這之前,我們需要利用以下兩行程式碼來取代預設的 Foundation 框架:
import SwiftUI
import VisionKit我們需要 SwiftUI 框架來使用 UIViewControllerRepresentable 協定,還有 VisionKit 來使用 VNDocumentCameraViewController。
接著就可以定義新的客製化型別,在這裡會使用跟檔名一樣的名稱:ScannerView:
struct ScannerView: UIViewControllerRepresentable {
}要使用 UIViewControllerRepresentable 這個協定的話,我們需要實作兩個方法。第一個方法是用來建立、設定、和回傳一個 UIKit 視圖控制器;而第二個方法是用來按 SwiftUI 環境的改變來更新視圖控制器。雖然第二個方法需要被定義出來,但是方法的 body 可以留白。
那就讓我們從第一個方法 makeUIViewController(context:) 開始吧。首先,建立一個新的 VNDocumentCameraViewController 實例,並回傳這個實例。
func makeUIViewController(context: Context) -> VNDocumentCameraViewController {
let scannerViewController = VNDocumentCameraViewController()
// Set delegate here.
return scannerViewController
}我們可以看到 VNDocumentCameraViewController 類別的 initializer 並不需要帶入參數。不過,為了能夠從視圖控制器取得掃描結果的圖片,我們需要將一個物件指定為掃瞄器的委派 (delegate),並實作幾個特定的方法。這個物件不會是 ScannerView 的實例,因為它必須是一個類別型別,我們在下文會再加以解釋。
接下來,在這邊加上第二個需要的方法,不過我們暫時還用不到它:
func updateUIViewController(_ uiViewController: VNDocumentCameraViewController, context: Context) { }Coordinator 類別
為了處理委派的方法,以及各種來自 UIKit 的訊息,我們需要在 UIViewControllerRepresentable 型別的 body 內部 建立一個 Coordinator 類別。
要建立這個類別,讓我們宣告一個儲存屬性 (stored property),並定義一個客製化的 initializer:
struct ScannerView: UIViewControllerRepresentable {
...
class Coordinator {
let scannerView: ScannerView
init(with scannerView: ScannerView) {
self.scannerView = scannerView
}
}
}這個 scannerView 屬性會存放著 ScannerView 實例,然後在初始化 (initialization) 時傳遞給 Coordinator 類別。我們一定要擁有這個屬性,因為這樣我們才可以讓 SwiftUI 知道掃描的動作甚麼時候完成。
接下來,讓我們開始初始化 Coordinator 實例。要初始化 Coordinator 實例,我們需要先實作另外一個 UIViewControllerRepresentable 方法。在 ScannerView 結構裡面、Coordinator 類別外面,加上這段程式碼:
struct ScannerView: UIViewControllerRepresentable {
...
func makeCoordinator() -> Coordinator {
Coordinator(with: self)
}
}現在,我們可以將委派物件設置給 VNDocumentCameraViewController 實例。回到 makeUIViewController(context:) 方法,將 // Set delegate here. 這段註解替換成以下的程式碼:
scannerViewController.delegate = context.coordinator你會注意到,在這個方法中的 context 參數可以直接存取 coordinator 物件。當你完成之後,makeUIViewController(context:) 方法看起來會是這樣:
func makeUIViewController(context: Context) -> VNDocumentCameraViewController {
let scannerViewController = VNDocumentCameraViewController()
scannerViewController.delegate = context.coordinator
return scannerViewController
}進行到這一步,我們其實是在告訴 scannerViewController,Coordinator 實例是它的委派物件。不過,Xcode 似乎顯示了幾個錯誤,因為我們還沒有實作任何委派的方法,讓我們在下部分來實作吧!
委派方法
回到 Coordinator 類別,讓我們從更新標頭 (header) 開始:
class Coordinator: NSObject, VNDocumentCameraViewControllerDelegate {
...
}現在,Coordinator 類別遵從 VNDocumentCameraViewControllerDelegate 協定,協定包含了我們需要在這裡實作的委派方法定義。另外,Coordinator 也繼承了 NSObject 類別,以滿足 VNDocumentCameraViewControllerDelegate 協定的要求;因此它也遵從 NSObjectProtocol 協定。事實上,我們必須選擇實作一系列 NSObjectProtocol 所需要的方法,或是單純地繼承 NSObject 類別;很明顯後者是比較方便。
在這邊,我們有三個必要實作的委派方法。每個都會被 VNDocumentCameraViewController 實例所呼叫,來處理不同的事件:
- 當已經掃描好的圖片需要處理,就會呼叫第一個委派方法。
- 當使用者取消了掃描工作,就會呼叫第二個委派方法。
- 當有錯誤發生,而其實沒有掃描好的圖片需要處理,就會呼叫第三個委派方法。
讓我們先初步實作第二和第三個委派方法:
class Coordinator: NSObject, VNDocumentCameraViewControllerDelegate {
...
func documentCameraViewControllerDidCancel(_ controller: VNDocumentCameraViewController) {
}
func documentCameraViewController(_ controller: VNDocumentCameraViewController, didFailWithError error: Error) {
}
}兩個方法的 body 都只有一行程式碼,用來通知 SwiftUI 個別的結果。不過,我們待會再回到這個部分。我們還要實作第一個委派方法,而這個方法是最有趣而重要的一個:
class Coordinator: NSObject, VNDocumentCameraViewControllerDelegate {
...
func documentCameraViewController(_ controller: VNDocumentCameraViewController, didFinishWith scan: VNDocumentCameraScan) {
}
}在上列的方法裡,scan 參數以圖片形式存放了所有掃描好的文件。每個掃描的結果都被視為一個頁面 (page),這就是為什麼我們說掃描好的頁面會以圖片的形式回傳。
為了存放所有掃描好的頁面,我們需要先建構一個 UIImage 物件的 collection。接著,我們會使用一個簡單的迴圈 (loop) 來訪問每個頁面,並儲存圖像。Scan 中的 pageCount 參數定義了可用頁面的數量,也就是迴圈的上限。讓我們看看上述實作的程式碼:
func documentCameraViewController(_ controller: VNDocumentCameraViewController, didFinishWith scan: VNDocumentCameraScan) {
var scannedPages = [UIImage]()
for i in 0..<scan.pageCount {
scannedPages.append(scan.imageOfPage(at: i))
}
}完成以上的方法之後,我們就能夠以圖片形式取得所有掃描好的頁面。現在,我們只需要通知 SwiftUI 視圖掃描的結果即可!
與 SWiftUI 的視圖溝通
看看上面三個委派方法,其實它們並沒有與 SwiftUI 視圖溝通,因此讓我們針對這部分來做些改變。
我們會使用行為處理器 (action handlers),又或是稱為閉包 (closures),來把掃描結果回傳給 SwiftUI。這些處理器會被 Coordinator 類別所呼叫,但是它們會在 ScannerView 結構的 initializer 當中被實作。不過,我們首先要宣告它們,才可以繼續實作,而宣告的位置就是在 ScannerView 結構裡面。
我們先從簡單的開始,在使用者取消掃描時,就會呼叫這個處理器:
struct ScannerView: UIViewControllerRepresentable {
var didCancelScanning: () -> Void
...
}這個行為處理器不需要任何的引數 (argument)。我們只為一件事情而呼叫它,而實作也只會針對這個需求而已。然而,第二個處理器就不是這麼簡單了。在這邊我們需要處理兩種情況:掃描成功或是失敗,然後按情況回傳掃描好的頁面,或是發生的錯誤。
最好的方式就是回傳一個 Result 參數。Result 是 Swift 一個特別的型別,用來表示成功或是失敗的結果,並允許我們以關聯值 (associated value) 來傳遞任意值或是錯誤物件。在這個例子當中,我們會在成功時傳遞一組掃描好的圖片,在失敗時傳遞出一個錯誤。
明白上述概念後,是時候宣告第二個處理器了,這次我們有一個 Result 型別的引數。這個語法看起來有點複雜,但是內容其實相當簡單:
struct ScannerView: UIViewControllerRepresentable {
var didFinishScanning: ((_ result: Result<[UIImage], Error>) -> Void)
...
}在 Result<[UIImage], Error> 中,第一個型別是成功時我們想要傳遞的資料,而第二個就是一個錯誤型別。
在宣告了前面兩個處理器之後,讓我們回到 Coordinator 類別來使用它們。現在,你會明白為什麼我們在 Coordinator 裡會宣告 scannerView 參數;因為我們將會透過這個參數,來存取剛剛實作的兩個行為處理器。
首先,從簡單的 documentCameraViewControllerDidCancel(_:) 委派方法開始。讓我們如下更新程式碼,讓它在 body 中呼叫 didCancelScanning:
func documentCameraViewControllerDidCancel(_ controller: VNDocumentCameraViewController) {
scannerView.didCancelScanning()
}接下來,讓我們處理關於錯誤的委派方法。你會看到,我們呼叫 didFinishScanning 處理器時,使用的是 .failure Result 型別,並且傳入一個錯誤為引數。
func documentCameraViewController(_ controller: VNDocumentCameraViewController, didFailWithError error: Error) {
scannerView.didFinishScanning(.failure(error))
}最後,讓我們到 documentCameraViewController(_:didFinishScanning:) 委派方法,向 Result 型別為 .success 的情況提供 scannedPages 陣列 (Array)。
func documentCameraViewController(_ controller: VNDocumentCameraViewController, didFinishWith scan: VNDocumentCameraScan) {
...
scannerView.didFinishScanning(.success(scannedPages))
}到這邊 ScannerView 終於完成了!現在,我們可以使用它取得掃描好的頁面,並繼續實作文字辨識的部分。
展示掃瞄器
打開 ContentView.swift 檔案,並且到 body 最後實作表單的部分:
.sheet(isPresented: $showScanner, content: {
})在這個表單的內容裡面,我們要初始化一個 ScannerView 實例。我們提供的兩個參數都是閉包。
.sheet(isPresented: $showScanner, content: {
ScannerView { result in
} didCancelScanning: {
}
})如果使用者取消了掃描工作,我們只需要讓表單從螢幕上消失即可。我們可以將 showScanner @State 參數的值設定成 false:
.sheet(isPresented: $showScanner, content: {
ScannerView { result in
} didCancelScanning: {
// Dismiss the scanner controller and the sheet.
showScanner = false
}
})不過,第一個閉包更加有趣,因為這邊我們處理掃描結果的地方。記得我們在 didFinishScanning 處理器中傳遞了 Result 值為引數,而上面的閉包中 result 值就代表這個引數。我們必須要檢查 result 實際的值,並按情況來執行適當的動作。
為了取得 Result 值以及其關聯值,我們需要在這裡使用 switch 陳述式:
switch result {
case .success(let scannedImages):
case .failure(let error):
}在成功的情況下,scannedPages 值就會包含所有掃描好的圖片。而在失敗的情況下,error 值就會包含真正的 Error 物件。
在取得這些關聯值之後,處理錯誤的方式就因人而異,不同的 App 也會有不同的處理方式。因為我們只是在實作一個範例 App,因此不會針對錯誤做額外的處理,就這樣印出即可:
switch result {
case .success(let scannedImages):
case .failure(let error):
print(error.localizedDescription)
}在真正實作 App 的時候,當然不應該只將錯誤印出!我們應該好好處理錯誤,有需要的話,也可以顯示訊息告訴使用者掃描失敗。如果你沒有這樣做,使用者就會預計得到掃描頁面,也不明白為什麼沒有得到掃描結果;這是非常差的使用者體驗。
至於在成功的情況下,我們會加上 break 關鍵字,來讓 Xcode 停止顯示錯誤:
switch result {
case .success(let scannedImages):
break
case .failure(let error):
print(error.localizedDescription)
}我們會在實作完辨識文字的部分之後,再回來這個方法。之後我們會將 break 指令替換掉,以提供 scannedPages 值來初始化辨識工作。
最後還有一件事情要處理,就是在 switch statement 後面,再次將 showScanner @State 參數設定為 false。如此一來,表單在執行完掃描之後就會關閉。加上這個部分之後,表單的內容會是這樣:
.sheet(isPresented: $showScanner, content: {
ScannerView { result in
switch result {
case .success(let scannedPages):
break
case .failure(let error):
print(error.localizedDescription)
}
showScanner = false
} didCancelScanning: {
showScanner = false
}
})現在我們可以試試這個範例 App,但是記得要在有相機的實機上來執行,否則 App 將會崩潰;這也是在真實 App 中需要注意的事情。當這個表單顯示之後,你會看到 scannner 視圖控制器。不過,可想而知即使你進行掃描,也不會發生任何事情。
一個基本的資料模型
在我們實作文字辨識之前,先來建立一個小資料模型,來存放辨識後的文字。按下 Cmd+N 來建立一個新的 Swift 檔案,取名為 Model.swift。
檔案準備好之後,讓我們打開並進行編輯。首先加入以下類別:
class TextItem: Identifiable {
}或許你會想:為甚麼 TextItem 是一個類別,而不是結構呢?這麼做是有目的的,因為在文字辨識時,我們需要它在一個地方宣告一些物件,然後在另一個地方修改那些物件,再以引數進行傳遞。如果使用結構,就會很難這樣實作。
你會看到我們定義 TextItem 類別遵從 Identifiable 協定。這個也是有目的的,是為了在 SwiftUI 列表視圖中使用 TextItem 實例時更容易。
Identifibale 型別有一個要求,就是必須宣告一個名為 id 的屬性。這個屬性可以是任意的型別,但是必須要讓物件在一組類似的物件中能夠被獨立辨認出來。
讓我們宣告這個屬性,並且定義為一個字串:
class TextItem: Identifiable {
var id: String
}在這之後,我們要加上另一個屬性,用來存放辨識出來的文字為字串:
class TextItem: Identifiable {
...
var text: String = ""
}接著,我們需要實作一個 initializer 方法。在 initializer 裡面,我們會賦予 id 屬性一個獨特的值。
這個獨特的值將會是一個 UUID 字串,也就是我們需要的全域獨立數值 (universaly unique value)。對於像這篇教學的小 App 來說,這個辦法沒甚麼問題,不過我不建議你在大型專案當中使用。
好,讓我們來實作初始化方法,在方法中我們會詢問系統,並取得一個 UUID 值來賦予 id 屬性:
init() {
id = UUID().uuidString
}以上就是我們的小小資料模型,整段的實作如下:
class TextItem: Identifiable {
var id: String
var text: String = ""
init() {
id = UUID().uuidString
}
}在上面的程式碼中,我們也建立了一個客製化類別。這個類別只會有一個參數,就是一組 TextItem 物件。這個類型也會遵從 ObservableObject 協定,讓我們可以使用 @Published 屬性包裝器(property wrapper) 來標記這個 TextItems 陣列。如此一來,我們就可以使用 Combine,來通知 SwiftUI 視圖有關陣列的改變。
以下是這個類型:
class RecognizedContent: ObservableObject {
@Published var items = [TextItem]()
}以上就是要在 Model.swift 所加上的內容。現在,我們可以開始使用這些客製化型別了。讓我們回到 ContentView.swift 檔案,在 ContentView 結構的最上方,宣告以下屬性:
struct ContentView: View {
@ObservedObject var recognizedContent = RecognizedContent()
...
}我們剛剛添加的這行程式碼,建立了 RecognizedContent 實例,並存放在 recognizedContent 屬性中。因為我們用 @ObservedObject 屬性包裝器標記了它,所以任何 items 陣列(以 @Published 參數包裝器進行標記)的變化,都會通知 SwiftUI 視圖。
實作文字辨識
為了在範例 App 加上文字辨識的功能,我們需要加上一個新的檔案。跟之前一樣,按下 Cmd+N 來建立新的 Swift 檔案,並且命名為 TextRecognition.swift。
在這個全新的檔案中,我們需要匯入兩個框架,來取代預設的 Foundation 框架:
import SwiftUI
import VisionVision 框架將會為我們提供所有需要使用的 API。而我們只需要準備好辨識流程,然後就可以把真正的工作交給 Vision 框架。
不過,讓我們開始建立一個新的客製化型別:一個名為 TextRecognition 的結構:
struct TextRecognition {
}在 TextRecognition 型別中,我們需要宣告三個屬性。第一個是一組 UIImage 物件,也就是存放著需要辨識的掃描頁面的陣列。很明顯地,這就是我們之前實作的 ScannerView 掃描所得的圖片。
第二個屬性是在 ContentView 裡初始化的 RecognizedContent 實例。像之前一樣,我們會利用 @ObservedObject 參數包裝器標記這個屬性,不過我們不需要初始化它,因為這個實例在 ContentView 中會以引數的形式提供。
第三個是一個行為處理器,在辨識處理結束的時候會被呼叫。要注意文字辨識是需要花時間的工作,所以會在背景佇列 (background queue) 中進行,而且完成時間是無法確定的。所以這邊處理的是一個非同步 (asynchronous) 的操作,我們會在處理器完成文字辨識的時候通知 ContentView 。
以下是剛剛所提到的三個屬性:
struct TextRecognition {
var scannedImages: [UIImage]
@ObservedObject var recognizedContent: RecognizedContent
var didFinishRecognition: () -> Void
}接下來,就讓我們專注在真正的辨識程序。一般來說,以下幾個步驟是必要的處理過程:
我們會為每個需要處理的掃描圖像建立一個特別的物件:一個 VNImageRequestHandler 實例。這個物件的用途是要取得圖片,並透過執行一個 Vision 請求 (request) 來執行辨識。
Vision 請求不只是一個模糊的名詞。對於開發者來說,我們有幾個動作需要執行,而這就是我們的第二個步驟。進一步來說,我們需要啟動一個 VNRecognizeTextRequest 物件,來請求 Vision 框架實際執行辨識動作。
上述的工作會以非同步的方式執行,而在工作結束的時候,我們就會得到請求的結果,或是如果辨識出現錯誤時,就會得到一個錯誤物件。這時候,我們就可以針對辨識出的文字,應用各種客製化的邏輯了。在這篇教學及範例 App 中,我們會在這裡把圖像中辨識出的文字存放在 TextItem 實例裡。
請注意,在執行識別請求之前,我們還可以配置一些屬性。在後面的部分,我們會配置幾個屬性。
我們將會在 TextRecognition 結構中實作兩個客製化方法,來管理以上所有內容。而我們會從最後介紹的部分開始,那就是文字請求物件。
實作一個文字辨識請求
首先,讓我們定義以下的私有方法 (private method):
private func getTextRecognitionRequest(with textItem: TextItem) -> VNRecognizeTextRequest {
}我們可以看到這裡的參數為 TextItem 實例。因為 TextItem 是一個類別,如果在方法內它有任何變化,就會反映到呼叫者。另外,我們也標記了這個方法為私有,因為我們只想這個方法在客製化類別內可見,而不要被外部使用。
另外,這裡回傳的是一個 VNRecognizeTextRequest 物件,這個請求將會被之前所提到的 VNImageRequestHandler 物件所使用。在這裡,我們將會建立、設定、並且處理這個文字請求物件,不過我們暫時不會使用這個物件。我們在下一個部分實作好另一個方法之後,才會使用這個物件。
在這邊,先建立一個文字辨識請求物件:
let request = VNRecognizeTextRequest { request, error in
}如前文所述,文字辨識是一個非同步的操作,所以在請求完成時,我們會在一個閉包中獲取執行的結果。這個閉包有兩個參數,第一個是 VNRequest 物件,其中包含著辨識結果,而第二個是可能會發生的錯誤物件。
我們先略過錯誤的情況,因為我們不會對它做太多的處理,畢竟這只是一個範例 App,我們只會印出錯誤訊息。不過記得,在真實的 App 當中,我們不應該只是印出錯誤訊息。
let request = VNRecognizeTextRequest { request, error in
if let error = error {
print(error.localizedDescription)
return
}
}上面的 if-let 宣告中直接 return,可以停止執行閉包中的其他程式碼。
接著,讓我們處理辨識結果。我們可以透過 results 屬性來存取辨識結果,那是一個包含 VNRecognizedTextObservation 物件的陣列。這樣的物件包含了原始圖片的文字區域資訊,我們可以用以下的方式取得內容:
guard let observations = request.results as? [VNRecognizedTextObservation] else { return }Results 的值可能為空值,所以我們需要像上方程式碼這樣解開這個選擇值 (option value)。解開了的文字觀察 (text observation) 物件會被儲存至 observations 常數。
接著,我們要遍歷每個觀察物件,並保存辨識到的文字。這邊大家需要了解這是透過機器執行的文字辨識,不是真人辨識,所以針對圖片中的文字部分,它可能會以不同的正確程度,回傳多於一個辨識結果。而我們想要求最準確的辨識結果,因此我們會如此編寫程式碼:
observations.forEach { observation in
guard let recognizedText = observation.topCandidates(1).first else { return }
} 上面使用的 topCandidates(_:) 方法可以取得真實辨識出來的文字。而我們提供的引數,是指我們在這次觀察中需要取得多少筆辨識結果。請注意,這個數字不能超過 10,而且得到的結果可能會少於所請求的數量。
儘管如此,在上述程式碼中,guard 語句所定義的 recognizedText 常數包含了實際的辨識文字,因此,現在我們可以繼續執行閉包,並且將它儲存在 textItem 變數中:
observations.forEach { observation in
...
textItem.text += recognizedText.string
textItem.text += "\n"
}如果沒有像上面這樣加入最後一行程式碼,散落在多行的文字會全部被儲存在 textItem 物件的 text 屬性中,而完全沒有斷行。當然你可以按照需要的方式來處理這些文字,畢竟這沒有一個特定的做法。
請注意,這裡的 recognizedText 常數是一個 VNRecognizedText 物件,我們可以透過它的 string 屬性來取得真實的文字。
總結以上內容,請求物件會像這樣:
let request = VNRecognizeTextRequest { request, error in
if let error = error {
print(error.localizedDescription)
return
}
guard let observations = request.results as? [VNRecognizedTextObservation] else { return }
observations.forEach { observation in
guard let recognizedText = observation.topCandidates(1).first else { return }
textItem.text += recognizedText.string
textItem.text += "\n"
}
}在這個閉包的結尾之後,我們可以針對請求物件做一些設置:
request.recognitionLevel = .accurate
request.usesLanguageCorrection = true第一個屬性是用來設置文字辨識的精準度。.accurate 明顯會回傳更好的辨識結果,但是也會花更多時間來執行。另一個選擇是 .fast,而相對要捨棄的就是精準度了。你可以按需要來選擇適合的設置,我建議你可以在教學結束之後試試不同的設置,看看結果會有甚麼不同。
第二個屬性是用來告訴 Vision 框架,應否在辨識的時候進行語言修正 (language correction)。當設置為 true 的時候,所得到的結果就會更準確,但是會花更多的時間來執行。設置為 false 的話,就不會進行語言修正,但結果的準確度就可能比較低。
最後,別忘記回傳剛剛建立且設置好的 request 物件:
return request完整的 getTextRecognitionRequest(with:) 方法如下:
private func getTextRecognitionRequest(with textItem: TextItem, currentImageIndex: Int) -> VNRecognizeTextRequest {
let request = VNRecognizeTextRequest { request, error in
if let error = error {
print(error.localizedDescription)
return
}
guard let observations = request.results as? [VNRecognizedTextObservation] else { return }
observations.forEach { observation in
guard let recognizedText = observation.topCandidates(1).first else { return }
textItem.text += recognizedText.string
textItem.text += "\n"
}
}
request.recognitionLevel = .accurate
request.usesLanguageCorrection = true
return request
}執行文字辨識
相信進行到這邊,你也非常清楚文字辨識是一件非常花時間的事情,而且我們無法確定需要多少時間來完成。要進行這樣耗時的工作,我們自然不希望主線程 (main thread) 保持忙碌的狀態,反而希望 App 可以保持流暢,而且在文字辨識的過程中仍然可以被使用。為了能夠達到這個目的,我們需要利用背景分派佇列(background dispatch queue),在背景執行所有任務。這就是我們需要定義的第二個方法:
func recognizeText() {
}跟之前的方法不同,這個方法不會被標記成私有。我們需要這個方法能夠被 TextRecognition 以外的類別存取,因為這個方法會啟動整個文字辨識的流程。
就像之前提到的,我們的第一步就是定義一個新的背景佇列,然後利用它來非同步地執行所有操作:
let queue = DispatchQueue(label: "textRecognitionQueue", qos: .userInitiated)
queue.async {
}當這個佇列被初始化時,我們會提供兩個引數:可以是任意字串值的標籤、和服務品質 (quality of service) 的值。第二個引數定義了這個佇列在背景執行的優先權,.userInitiated 就是代表著最高優先權。
備註:如果你想了解關於分派佇列,可以參考這篇文章。
在佇列的 async 閉包中,我們將建立一個迴圈 for-in,用來迭代處理所有掃描好的影像。
for image in scannedImages {
}我在前文提過,我們會為每一個掃描好的圖片建立一個 VNImageRequestHandler 物件,這個物件會取得真實的圖片及前面所實作的文字辨識請求,並且啟動文字辨識的行為。要傳遞的圖片可以是各種型別,除了像我們在 scannedImages 陣列存放的 UIImage。
因此,在迴圈內的第一步,就是要從原本的 UIImage 取得 CGImage 物件,像是這樣:
guard let cgImage = image.cgImage else { return }由於 cgImage 屬性有機會是空值,所以我們必須像上述一樣使用 guard 陳述式(或 if-let)。
現在,CGImage 代表原始圖片之後,我們就可以初始化一個 VNImageRequestHandler 物件。我們會傳入一個 cgImage 物件為引數。
let requestHandler = VNImageRequestHandler(cgImage: cgImage, options: [:])第二個引數是一組選項的數組,有需要的話我們就可以針對不同選項來做設定。不過這邊我們不需要,所以傳入空的數組。
因為我們即將呼叫的 perform 方法可能會拋出錯誤,所以要在這裡將剩下的程式碼包在 do-catch 陳述式裡。我們也可以使用選擇值 (Optional Value) 來處理這個情況,不過使用 do-catch 會比較適合。
所以在 for-in 迴圈裡,我們會加上以下的程式碼:
do {
} catch {
print(error.localizedDescription)
}同樣地,我們沒有打算處理錯誤,不過在真實的 App 中請你自行處理。
在 do 程式碼中,我們先建立一個 TextItem 物件,用來儲存辨識好的文字,我們已經在前面的方法中處理好這部分的邏輯。
let textItem = TextItem()是時候使用 requestHandler 物件,來執行文字辨識的請求了:
try requestHandler.perform([getTextRecognitionRequest(with: textItem)])我們會在這裡呼叫 getTextRecognitionRequest(with:) 方法,並且傳入 textItem 來當做引數。不過請注意,我們是在一個陣列裡面呼叫方法的,因為 perform(_:) 方法可以接受一個陣列的請求(雖然我們只有一個請求)。最後,以上的這行程式碼說明了需要 do-catch 陳述式的原因,因為我們在 perform(_:) 方法之前標記了 try 關鍵字。
當目前圖片的文字辨識完成之後,辨識出來的文字會被儲存在 textItem 物件裡。這時候,我們就可以把它加在 TextRecognition 型別中 recognizedContent 屬性的 items 裡。還記得我們用 @ObservedObject 屬性包裝器把這個屬性標記了嗎?也就是說,SwiftUI 視圖會知道屬性的所有變化。也因為如此,這個參數的任何修改行為都必須在主線程執行。
DispatchQueue.main.async {
recognizedContent.items.append(textItem)
}最後,我們還需要在關閉佇列的閉包之前,在 for-in 迴圈呼叫 didFinishRecognition 處理器,來通知文字辨識已經完成了。
DispatchQueue.main.async {
didFinishRecognition()
}以下是 recognizeText() 方法的完整實作:
func recognizeText() {
let queue = DispatchQueue(label: "textRecognitionQueue", qos: .userInitiated)
queue.async {
for image in scannedImages {
guard let cgImage = image.cgImage else { return }
let requestHandler = VNImageRequestHandler(cgImage: cgImage, options: [:])
do {
let textItem = TextItem()
try requestHandler.perform([getTextRecognitionRequest(with: textItem)])
DispatchQueue.main.async {
recognizedContent.items.append(textItem)
}
} catch {
print(error.localizedDescription)
}
}
DispatchQueue.main.async {
didFinishRecognition()
}
}
}現在文字辨識的部分已經完成了!接下來,讓我們應用剛剛實作好的部分。
啟動文字辨識
現在回到 ContentView.swift 檔案,我們會在這裡建立一個 TextRecognition 結構的實例,並且啟動文字辨識的流程。這部分將會在使用者掃描完包含文字的圖片後執行。
回到表單內容的實作,之前我們在這裡加上了 switch 陳述式。在 .success 的情況下,我們暫時使用了 break 來處理掃描結果。
case .success(let scannedImages):
break是時候改好這裡的程式碼了,將 break 移除並且加上這行程式碼:
isRecognizing = trueisRecognizing 是一個在 ContentView 的屬性,它被 @State 屬性包裝器標記。它的用處是標示文字辨識的工作是否正在進行。當這個值為 true 時,就會顯示一個圓形的 progress 視圖;而當 isRecognizing 數值回復為 false 時,視圖就會消失。Progress 視圖已經在初始專案中建立好了。
現在可以初始化一個 TextRecognition 實例:
TextRecognition(scannedImages: scannedImages,
recognizedContent: recognizedContent) {
}第一個引數是一組從掃描結果所得到的 scannedImages 陣列,第二個是在 ContentView 結構中被宣告和建構的 recognizedContent 屬性。最後一個是在文字辨識完成後會執行的 didFinishRecognition 閉包。而在文字辨識完成的時候,我們需要將 progress 視圖隱藏,所以必須將 isRecognizing 屬性設置為 false。
TextRecognition(scannedImages: scannedImages,
recognizedContent: recognizedContent) {
// Text recognition is finished, hide the progress indicator.
isRecognizing = false
}上述的程式碼還不足以啟動文字辨識的程序,我們還需要呼叫 recognizeText() 方法。我們會在 TextRecognition 方法後面進行呼叫:
TextRecognition(scannedImages: scannedImages,
recognizedContent: recognizedContent) {
...
}
.recognizeText()這時,掃描結果在 .success 的情況下看起來會像這樣:
case .success(let scannedImages):
isRecognizing = true
TextRecognition(scannedImages: scannedImages,
recognizedContent: recognizedContent) {
// Text recognition is finished, hide the progress indicator.
isRecognizing = false
}
.recognizeText()不過,我們還沒有完成!回到 body 最開始的部分,你可以找到下列的註解:
// Uncomment the following lines:下列三行程式碼的註解是用來定義一個列表和其內容,讓我們移除這些註解:
List(recognizedContent.items, id: \.id) { textItem in
Text(String(textItem.text.prefix(50)).appending("..."))
}這個列表就是我們要讓 TextItem 類別遵從 Identifiable 協定的原因。我們將 id 屬性設定為 keypath,代表在 recognizedContent 屬性內 items 陣列每個物件的獨特識別符 (identifier)。
在列表中每個物件都是 Text,每個只顯示前 50 個掃描字元。我們可以利用 prefix(_:) 方法,來取得實際的文字,而回傳的數值會是的子字串 (SubString)。因此我們會將它作為引數來提供給 String 初始化器,而它最終會與 Text 一起使用。
最後,是時候來看我們的 App 能不能實際執行了!在實機上執行這個 App,並掃描一個或多個圖片。完成後,Progress 視圖會出現,也就是說 App 正在進行文字辨識。之後,你就會在列表得到掃描好的文字。
預覽辨識到的文字
這個列表只顯示辨識文字的前 50 個字元,主要有兩個原因:
- 保持列表流暢,避免讀取大量資料(像是要辨識非常長的文字)。
- 只顯示部分文字,並且讓使用者可以開啟另一個視圖,來顯示完整文字。
這個額外的視圖就在初始專案裡;就是在 TextPreviewView 檔案中,而我們不需要做額外的處理,因為已經實作完成了。不過,我們可以打開來看一下。
在這個檔案中有一個 text 屬性,它沒有預設值,所以我們需要在建構時傳入一個數值。
在使用者點擊列表上的物件時,我們會使用 TextPreviewView 來顯示完整的文字。然而,我們需要先改變 ContentView 中列表的內容。
特別注意,我們會將列表中的文本視圖 (Text View) 替換成 NavigationLink。這樣一來,我們就可以將 TextPreviewView 的實例推送到導航畫面。主詳細導航是透過 ContentView 最外層的畫面 NavigationView 來實作的。
這個 NavigationLink 視圖會將我們想展示的 SwiftUI 視圖當做參數,在這個範例中,就是 TextPreviewView 的實例:
NavigationLink(destination: TextPreviewView(text: textItem.text)) {
}這個閉包會包含一個可顯示在列表中每個物件的內容。這就是我們之前的 Text:
NavigationLink(destination: TextPreviewView(text: textItem.text)) {
Text(String(textItem.text.prefix(50)).appending("..."))
}改好程式碼之後,我們的列表會像這樣:
List(recognizedContent.items, id: \.id) { textItem in
NavigationLink(destination: TextPreviewView(text: textItem.text)) {
Text(String(textItem.text.prefix(50)).appending("..."))
}
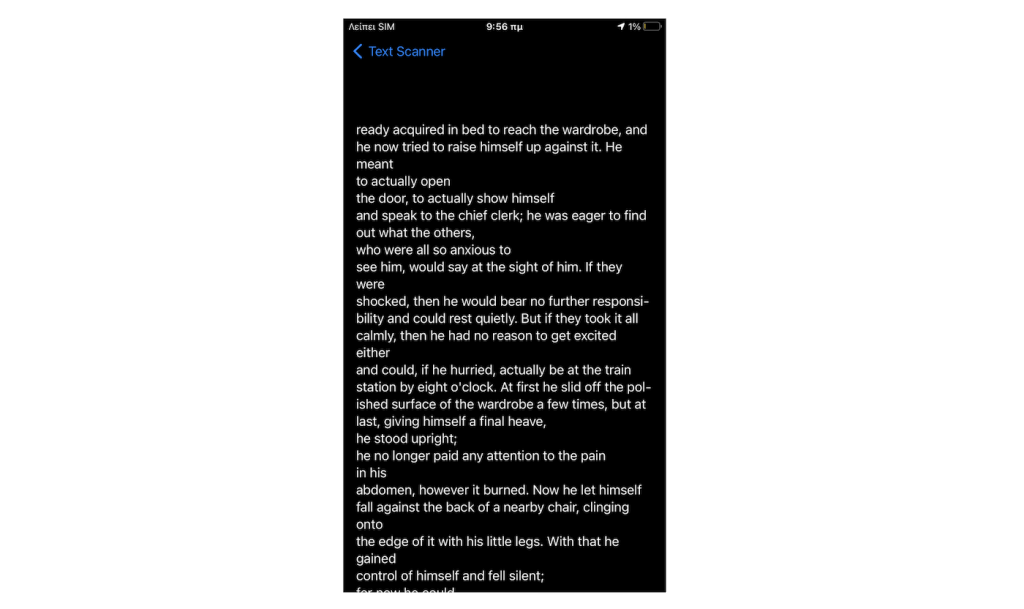
}再一次執行掃描和文字辨識的流程,而這次我們將可以點擊列表中的文字物件,並且導航至另一個可以看到完整文字內容的視圖。點擊在導航列上的 Back 按鈕,就可以回到上一頁。
結論
這篇詳細的教學結束了。在這篇文章中,我們接觸了兩個非常有趣又實用的主題:在 SwiftUI 中實作並使用 VNDocumentCameraViewController 來掃描圖片、以及使用 Vision 框架來辨識文字。當然,你不一定要完全跟著我們的步驟來實作,特別是實作辨識文字的部分。
總之,我只是在這裡分享了一般的實作方法,你可以以這篇教學為基礎,按需要來改變實作方法和細節。不管如何,我希望你喜歡這篇文章,也會覺得這篇文章的技巧和概念有用。謝謝你的閱讀!
你可以在 GitHub 上參考完整專案。
原文:How to Scan Images and Perform Text Recognition in SwiftUI Using VisionKit



