

Core ML 是 Apple 的手機機器學習框架 (machine learning framework),讓我們在設備上部署、運行和重新訓練模型。
我們可以利用 CoreML 實作很多東西,包括文本、聲音、甚至是圖像識別。
最重要的是,Apple 的電腦視覺框架 (computer vision framework) Vision 提供了多於 6 個內置模型,它更可以充當 Core ML 的容器 (container),讓我們更容易進行前處理 (preprocessing) 和推理 (inference)。
在這篇教學文章中,我們會在手機上實作機器學習最普遍的範例:iOS App 中的圖像分割 (Image Segmentation)。
圖像分割是深度學習 (deep learning) 的一種,可以讓我們分離圖像中的不同物件,是一種常用於自動駕駛汽車、或在圖像中某部分繪製邊界框的電腦視覺技術。

在接下來的部分,我們將使用 DeepLabV3 模型,在 SwiftUI App 中分割圖像的前景和背景部分。如此上來,我們就能夠添加、刪除、並修改圖像中的背景。畢竟,大家都會想用美麗的虛擬背景,來取代無聊的背景吧?
不要再浪費時間,讓我們開始吧!
取得 DeepLab Core ML 模型
之前,我們需要從 Pytorch 或 Tensorflow 等其他格式轉換為 Core ML 檔案,但現在 Apple 提供了可下載的 Core ML 檔案,可以直接在 Xcode 中使用。你可以從這裡獲取 DeepLabV3 CoreML 模型。
建立一個 Xcode 專案,以 SwiftUI 為使用者介面,並拖拉上述的 Core ML 檔案。你應該會看到如下的 Core ML 模型描述。
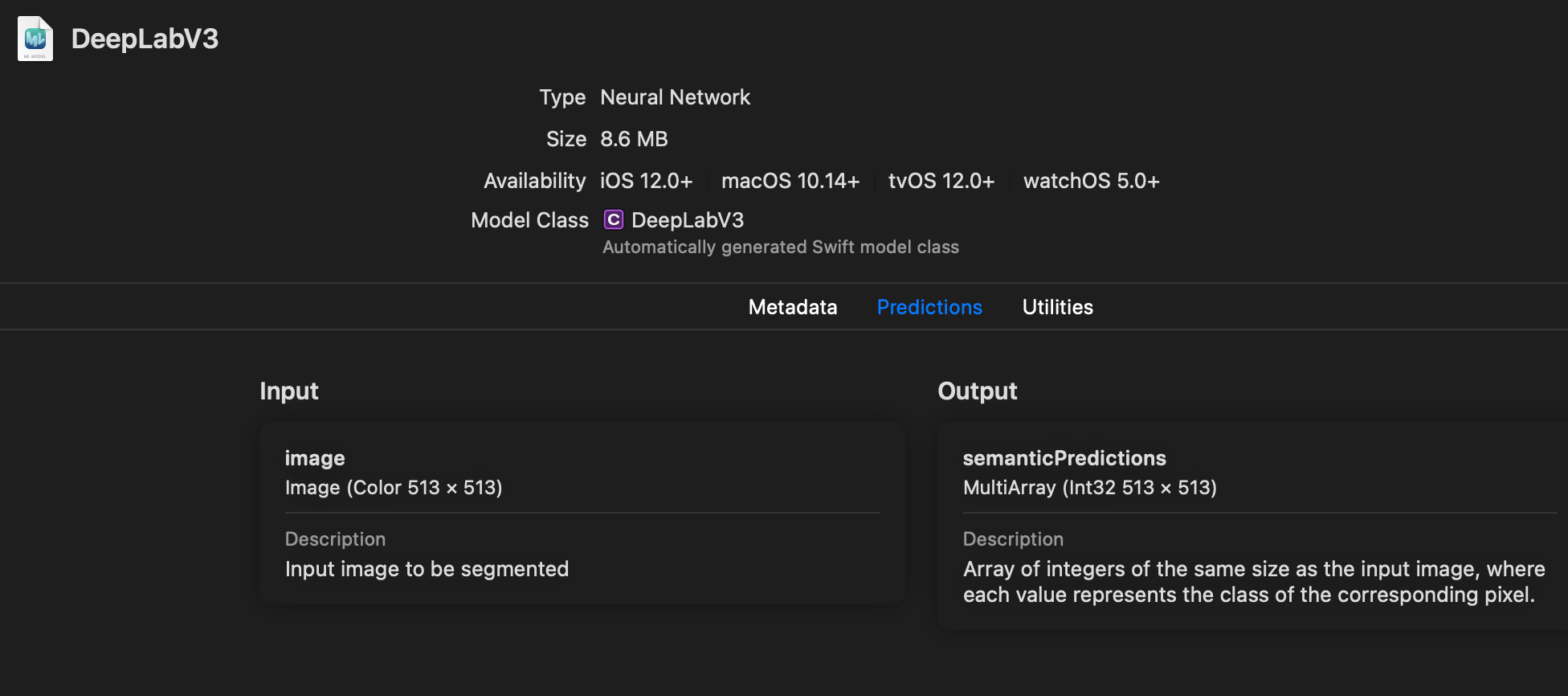
匯入型別是尺寸為 513 x 513 的 Image,而匯出的是相同大小的 MLMultiArray。我們很快就會看到,如何將匯出型別轉換為我們想要的圖像格式。
但首先,讓我們先設置好 SwiftUI 視圖。
設置 SwiftUI 視圖
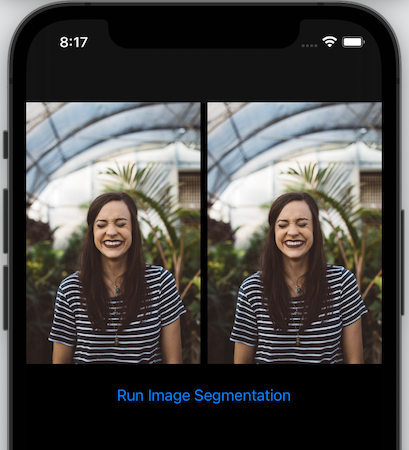
以下的程式碼會在屏幕上顯示兩個圖像,並平均地佈局。左邊是匯入的圖像,而右邊就會顯示圖像分割的結果。
struct ContentView: View {
@State var outputImage : UIImage = UIImage(named: "unsplash")!
@State var inputImage : UIImage = UIImage(named: "unsplash")!
var body: some View {
ScrollView{
VStack{
HStack{
Image(uiImage: inputImage)
.resizable()
.aspectRatio(contentMode: .fit)
Spacer()
Image(uiImage: outputImage)
.resizable()
.aspectRatio(contentMode: .fit)
}
Spacer()
Button(action: {runVisionRequest()}, label: {
Text("Run Image Segmentation")
})
.padding()
}
}
}
//.... more here
}備註:在 SwiftUI Button action 中呼叫的 runVisionRequest 函式,就是我們實作 Core ML 圖像分割的地方。
現在的 SwiftUI 視圖看起來應該是這樣的:
利用 Vision 請求執行圖像分割
接下來,讓我們設置 Vision 請求,以執行 DeepLabV3 圖像分割模型:
func runVisionRequest() {
guard let model = try? VNCoreMLModel(for: DeepLabV3(configuration: .init()).model)
else { return }
let request = VNCoreMLRequest(model: model, completionHandler: visionRequestDidComplete)
request.imageCropAndScaleOption = .scaleFill
DispatchQueue.global().async {
let handler = VNImageRequestHandler(cgImage: inputImage.cgImage!, options: [:])
do {
try handler.perform([request])
}catch {
print(error)
}
}
}我們可以從上面的程式碼中看到:
- 在 iOS 14 中,Core ML 已經棄用了預設的初始化方法 (
DeepLabV3())。因此,我們使用了新的init(configuration:)。 VNCoreMLModel是 Core ML 模型的容器。我們需要這種格式,來使用VNCoreMLRequest執行 Vision 請求。VNCoreMLRequest完成後,就會觸發 Completion Handler 函式。就我們的範例而言,我們已經在visionRequestDidComplete函式中定義了它。VNImageRequestHandler函式是觸發 Vision 請求的地方。我們在此處傳遞匯入圖像(而 Vision 會進行前處理以匹配模型匯入大小),然後在handler.perform函式中設置VNCoreMLRequest。
Retrieving The Segmentation Mask From The Output
VNImageRequest 完成後,我們可以在下面定義的 Completion Handler visionRequestDidComplete 中處理結果:
func visionRequestDidComplete(request: VNRequest, error: Error?) {
DispatchQueue.main.async {
if let observations = request.results as? [VNCoreMLFeatureValueObservation],
let segmentationmap = observations.first?.featureValue.multiArrayValue {
let segmentationMask = segmentationmap.image(min: 0, max: 1)
self.outputImage = segmentationMask!.resizedImage(for: self.inputImage.size)!
maskInputImage()
}
}
}我們可以從上面的程式碼中看到:
- Vision 圖像分析回傳的匯出是一個 Dictionary
VNCoreMLFeatureValueObservation。 - 包含分割圖 (segmentation map) 的
MLMultiArray就在 Dictionary 的第一個 Key中。 - 我們需要將 2D 陣列分割圖轉換成
UIImage。為此,我使用了 Matthijs Hollemans 的 CoreMLHelper 工具,來減少需要編寫的樣板程式碼。你可以在文章結尾的部分找到程式碼。 segmentationmap.image(min: 0, max: 1)MLMultiArray轉換為UIImage,然後我們就可以調整其大小,以配合初始圖像的大小。resizedImage是我編寫的UIImageSwift 擴充套件 (extension),你可以在這裡參考其程式碼。- 我們會在
maskInputImage()函式使用分割結果遮蔽 (mask) 初始圖像,以產生新背景。
現在,我們的分割遮罩 (segmentation mask) 已經準備好了:

太好了!分割遮罩對每組像素使用不同的顏色,將前景圖像與背景分開。
現在,讓我們利用 CoreImage 的技巧,來融合 (blend) 遮罩和圖像。
利用分割遮罩來轉換背景
CoreImage 是 Apple 的圖像處理庫,提供多種圖像濾鏡 (image filter)。
在這個範例中,我們需要融合分割遮罩到原本的圖像,以隱藏背景。此外,我們還想添加一個新的背景。
CoreImage 的 CIBlendWithMask 濾鏡就很適合我們的範例。以下是這個濾鏡的運作模式:

讓我們看看執行 CIBlendWithMask 濾鏡的 maskInputImage 函式:
func maskInputImage(){
let bgImage = UIImage.imageFromColor(color: .blue, size: self.inputImage.size, scale: self.inputImage.scale)!
let beginImage = CIImage(cgImage: inputImage.cgImage!)
let background = CIImage(cgImage: bgImage.cgImage!)
let mask = CIImage(cgImage: self.outputImage.cgImage!)
if let compositeImage = CIFilter(name: "CIBlendWithMask", parameters: [
kCIInputImageKey: beginImage,
kCIInputBackgroundImageKey:background,
kCIInputMaskImageKey:mask])?.outputImage
{
let ciContext = CIContext(options: nil)
let filteredImageRef = ciContext.createCGImage(compositeImage, from: compositeImage.extent)
self.outputImage = UIImage(cgImage: filteredImageRef!)
}
}我們可以從上面的程式碼中看到:
imageFromColor是一個 Swift 擴充套件,用來將純色 (solid color) 轉換為 UIImage。我們傳遞顏色、匯入圖像的大小和scale。設置相同的 Scale 非常重要,如此一來,就可以確保CGImage的大小與我們原本的圖像匹配,否則 CoreImage 的CIBlendWithMask濾鏡會產生扭曲的結果。CIBlendWithMask濾鏡需要三個參數的 Key:kCIInputImageKey、kCIInputBackgroundImageKey和kCIInputMaskImageKey。- 濾鏡回傳的
outputImage是一個 CIImage。要將其轉換為 UIImage,我們要先使用createCGImage將其轉換為 CGImage。
最終,匯出結果會是轉換了背景的圖像:

融合漸變背景到圖像中
除了純色外,你還可以添加任何圖像為背景。讓我們試試設置漸變顏色吧!
我參考了這個 StackOverflow 答案,來實作漸變顏色的 UIImage 擴充套件:

更進一步
在這篇文章中,我們學會了如何使用 Core ML 和 Vision,以 SwiftUI 實作刪除和轉換圖像的背景。你還可以更進一步,像是模糊背景、或僅隱藏背景的一部分。
比如說,以下我就把背景換成了艾菲爾鐵塔:

let bgImage = UIImage(named: "tower")!.resized(to: self.inputImage.size, scale: self.inputImage.scale)請記住,對背景圖像使用相同 scale 非常重要,這樣才能確保它可以適合視圖。
你可以在 GitHub 程式庫上下載專案的完整程式碼。
這篇文章到此為止,謝謝你的閱讀。