

你知道嗎,Apple 的全球開發者大會 (WWDC) 已經在上週舉行了!在這會議上,Apple 對現有的軟體和框架發佈了不少改進,而其中一個框架就是 Create ML 。
去年,Apple 推出了 Core ML,這工具讓你以最少的程式碼迅速將預先訓練好的機器學習模型導入 App 內。今年,Apple 透過 Create ML 這項工具,讓開發人員有能力透過 Xcode Playground 建立自己的機器學習模型 ,我們只需要一些數據就可以進行訓練了!雖然到目前為止,Create ML 僅支援文字、圖像和表格為數據,但大多數 ML 應用程式就是由這三種數據組成,因此應該能夠滿足你的需求了。現在,讓我向你展示如何使用這三種數據創建 ML 模型吧!
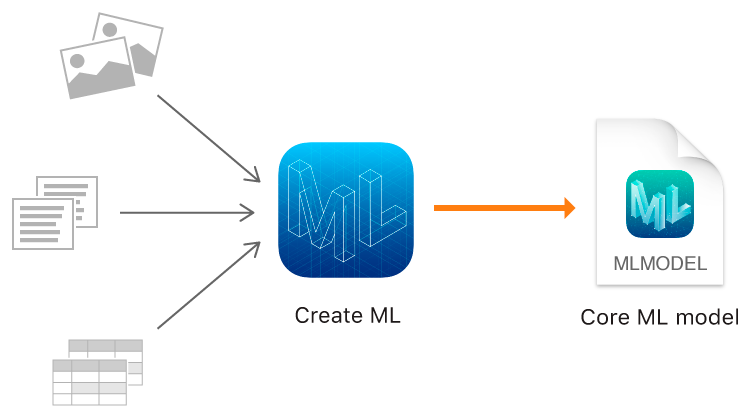
[圖片來源:Apple]
為何是 Create ML
你可能覺得疑惑,為什麼我會選擇 Create ML?這是因為 Create ML 能善用軟件內置的機器學習基礎設施。當你下載 iOS 12 或 macOS Mojave 時,你同時也在下載一些機器學習框架。這樣一來,當你創建自己的 ML 模型時,由於大部分數據已經存在於用戶設備上,就可佔用較少空間。
另一個 Create ML 受歡迎的原因,就是易於使用。你使用 Create ML 唯一需要做的,就是準備廣泛的數據集(文本或圖像)、編寫幾行程式碼,然後就可以運行 Playground 了!其他熱門工具如 Tensorflow 和 Caffe 需要大量程式碼,視覺化界面又不友善,Create ML 相比之下就簡單得多了。Create ML 全部內置於 Xcode Playgrounds 中,因此你會非常熟悉開發環境,而最好的是 ── 只用 Swift 程式語言就可以完成開發了!
先決條件
在本教學中,我只會展示如何使用 Create ML 創建自己的 ML 模型。如果想了解如何將 Core ML 模型導入 iOS App,你可以參考這篇教學。
圖像分類器模型
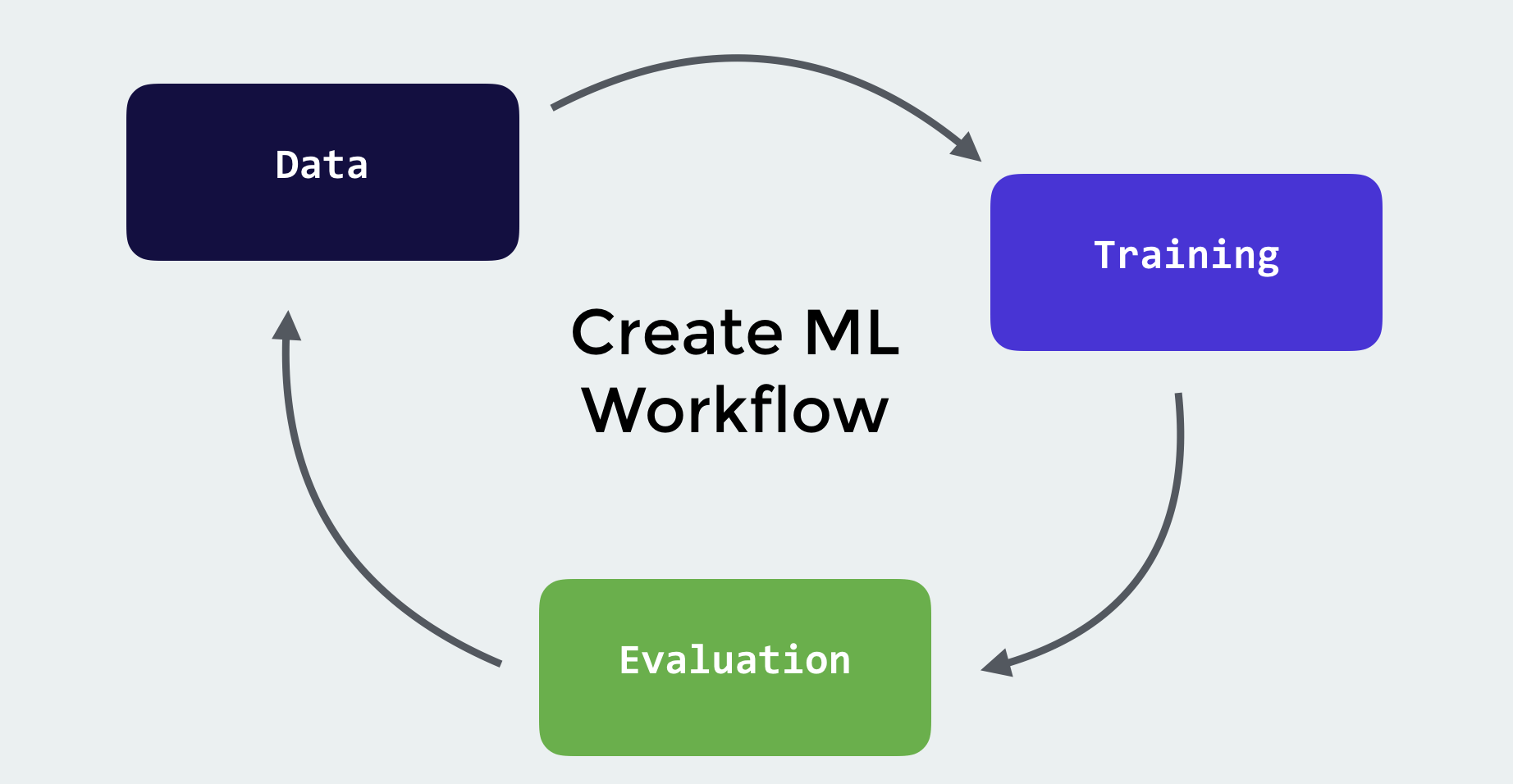
數據
讓我們從構建一個圖像分類器模型開始吧!我們可以隨意添加很多的圖像和標籤,但為了簡單起見,我們將構建一個辨識蘋果和香蕉的圖像分類器。你可以在這裡下載圖像。
資料夾內另有兩個資料夾,就是訓練數據 (Training Data)和測試數據 (Testing Data),兩個資料夾內均有蘋果和香蕉的圖片。在測試數據中有蘋果和香蕉圖像各 20 張,而訓練數據資料夾中就有各 80 張蘋果和香蕉圖像。我們將使用訓練數據中的圖像來訓練分類器,然後使用測試數據來測試其準確率。
如果你想構建自己的圖像分類器,就應該將數據集分成 80-20。把約 80% 圖像放在訓練數據資料夾,剩下的就放在測試數據資料夾。這樣一來,你就可以有更多數據來訓練分類器。在兩個資料夾中,將圖像分別放入其資料夾中,並根據圖像的類別標籤命名資料夾。
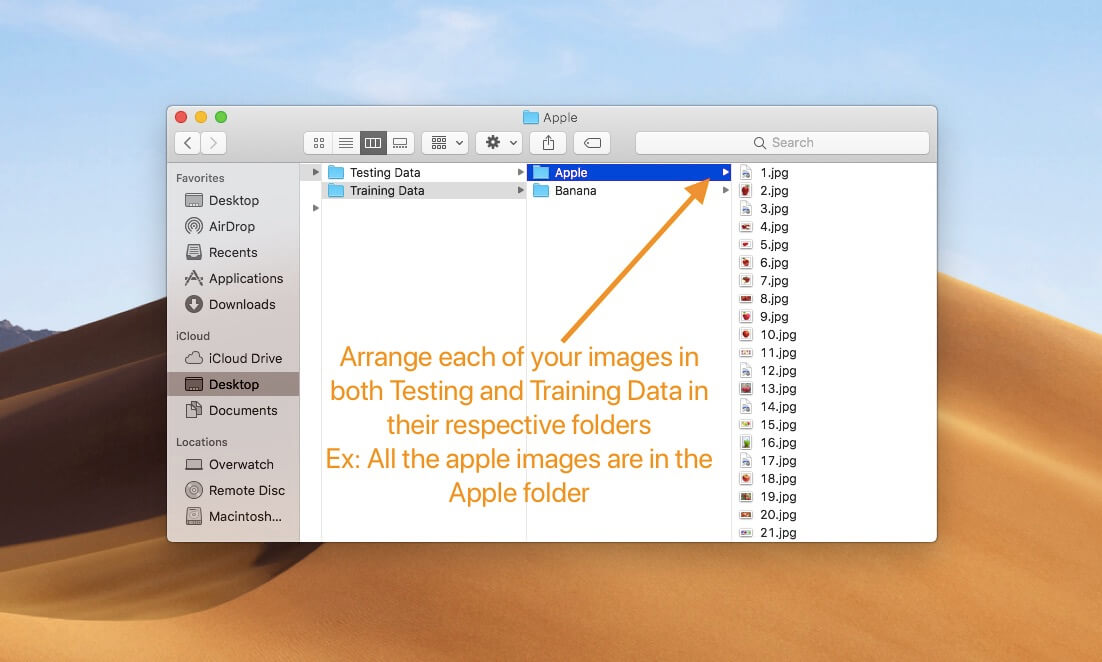
現在,打開 Xcode 並點擊 Get Started with a Playground。打開了新的視窗後,這一步非常重要 ── 在 macOS 頁籤下,選擇 Blank 模板,如下圖所示。
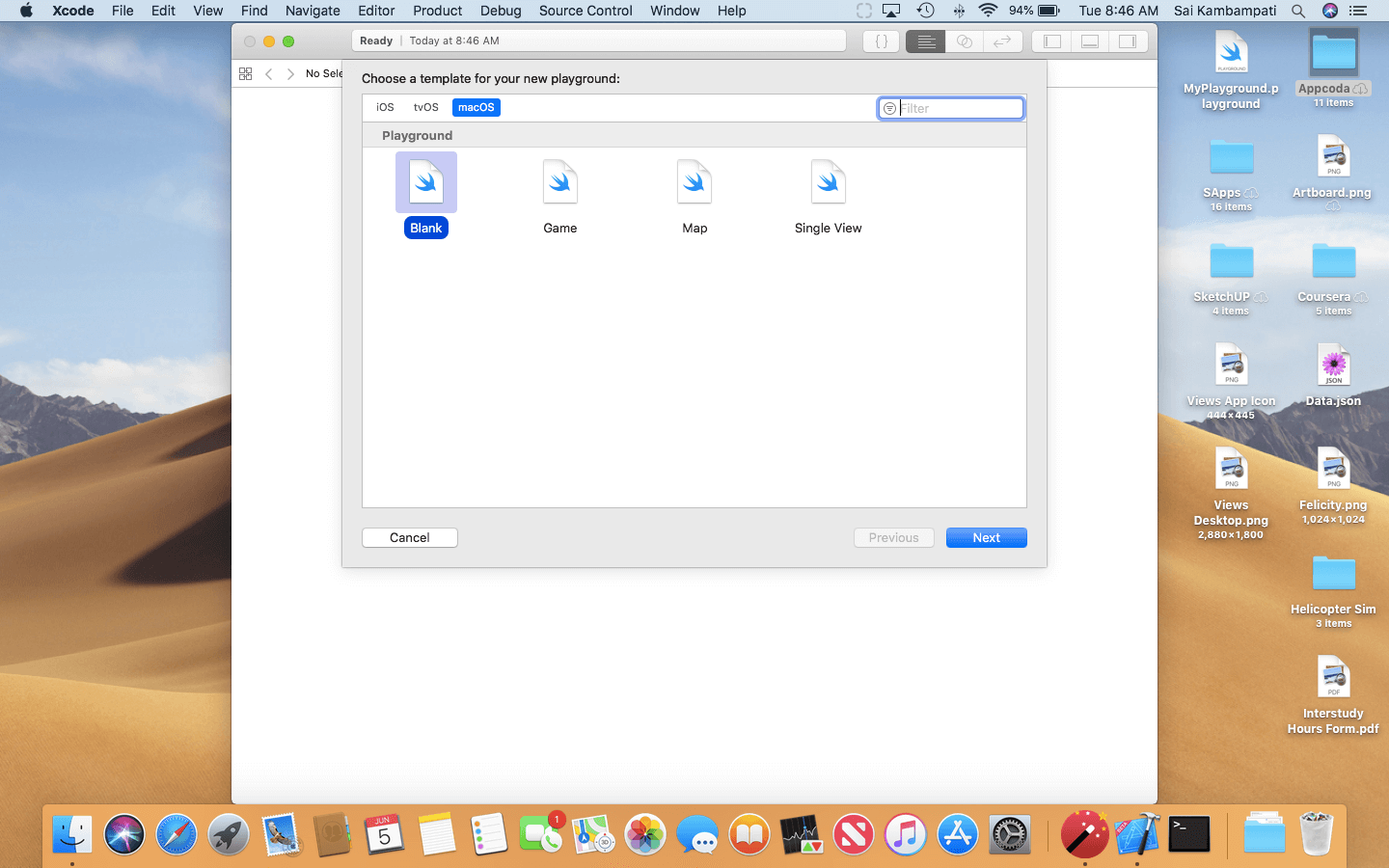
在 macOS 而非 iOS 中選擇空白模板是非常重要的,因為 iOS Playgrounds 並不支援 CreateML 框架。
命名 Playground 並將其儲存到任何地方。現在讓我們開始編寫程式碼!
程式碼
現在要說的事可能會讓你震驚,因為你所需要的就只是 3 行程式碼!刪除 Playground 上所有內容並輸入以下程式碼:
import CreateMLUI
let builder = MLImageClassifierBuilder()
builder.showInLiveView()
這樣就完成了!請確認你已經在 Xcode Playgrounds 啟用了 Live View 功能,這樣你就能夠看到視覺化界面!
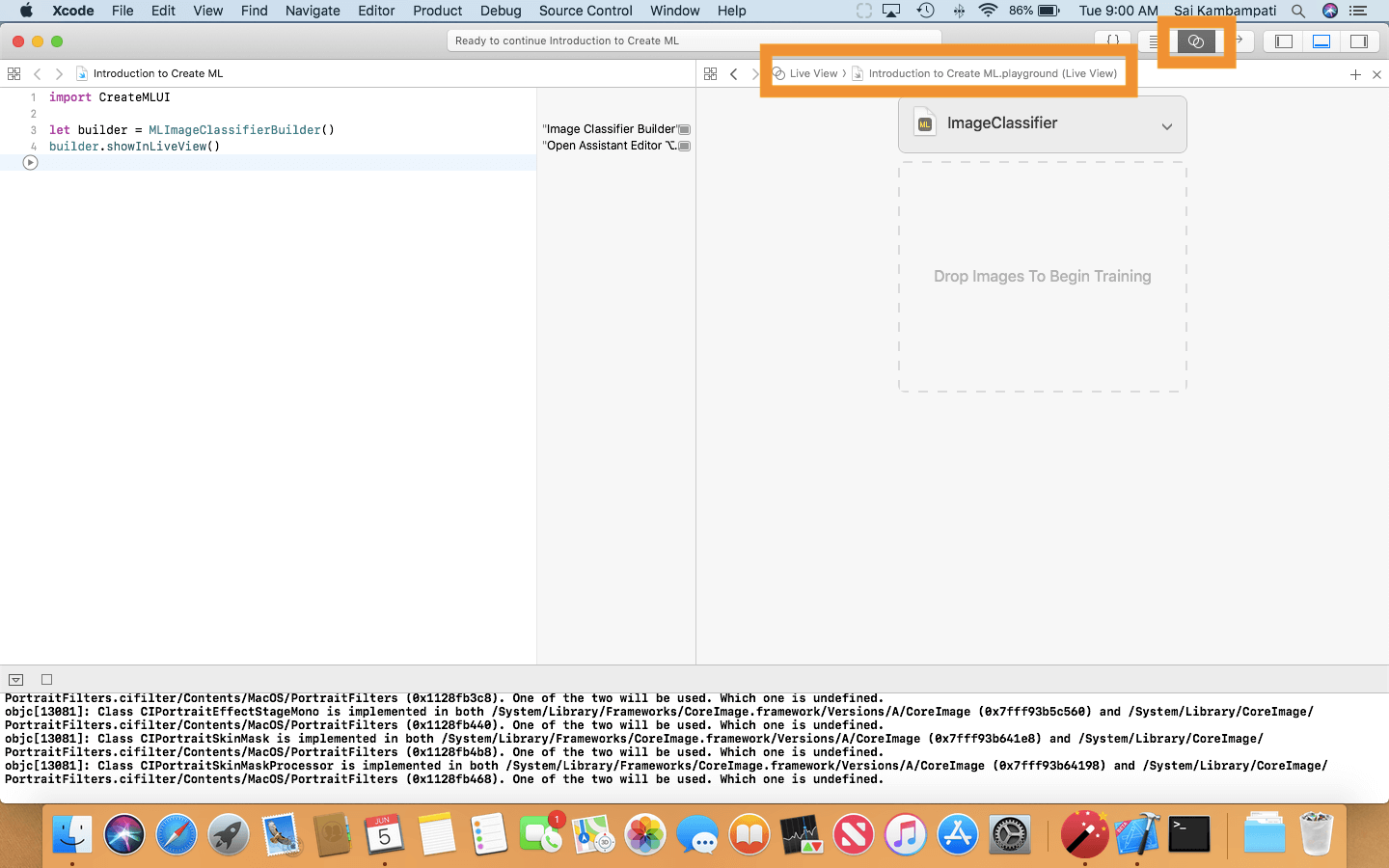
CreateMLUI 就像 CreateML 般是個框架,但它是有 UI 的。到目前為止,我們的 CreateMLUI 只能用於圖像分類,現在,來看看我們如何與 UI 進行互動吧!你會發現其實是很簡單的。
使用者介面 (UI)
在 Live View 中,你會看到我們需要先放下圖像才能開始!這很簡單,把整個訓練數據資料夾放入該區域。
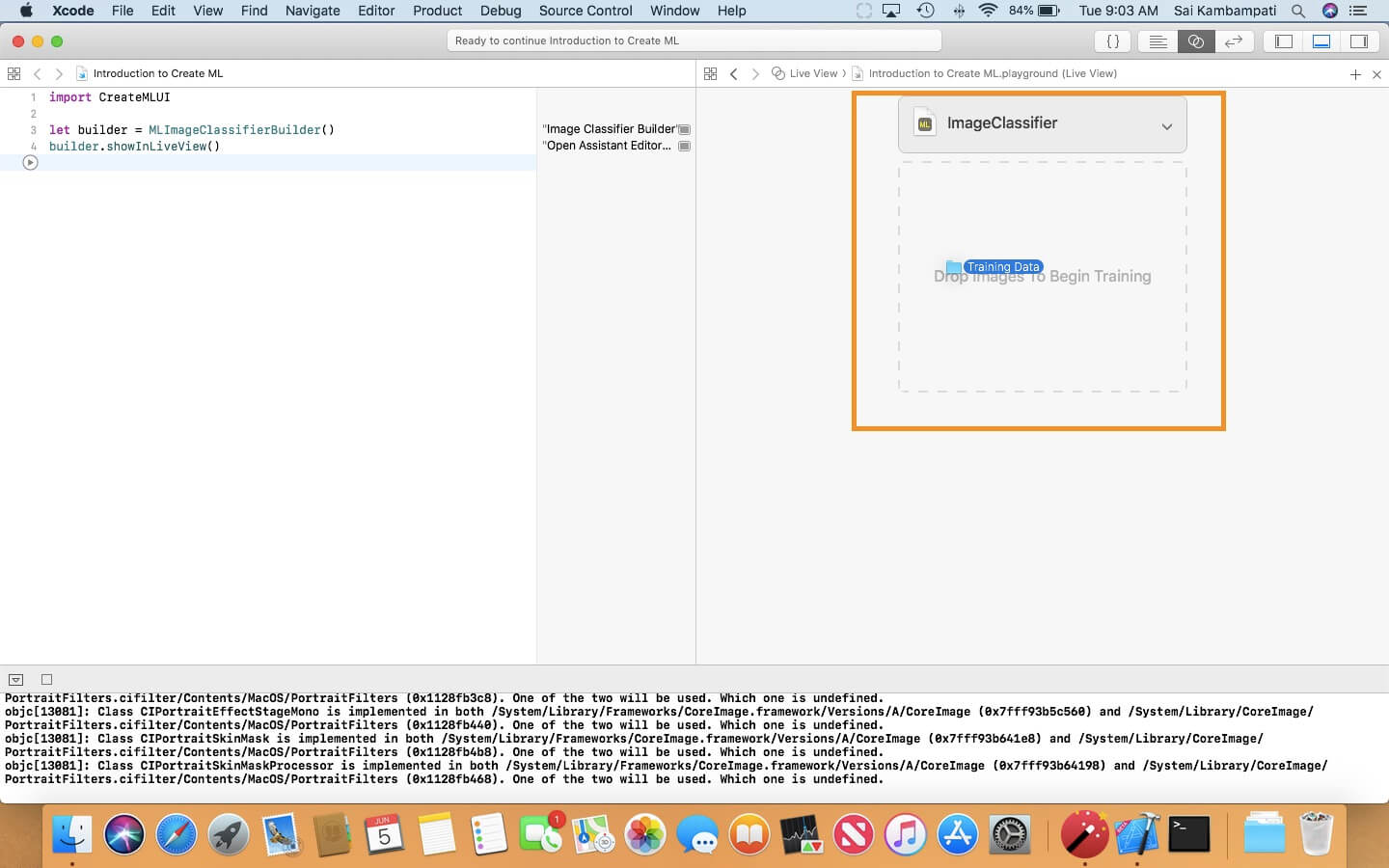
放下資料夾後,你會看到 Playground 開始訓練圖像分類器。在控制台中,你會看到在多少時間內處理了多少圖像,以及數據訓練完成的百分比。
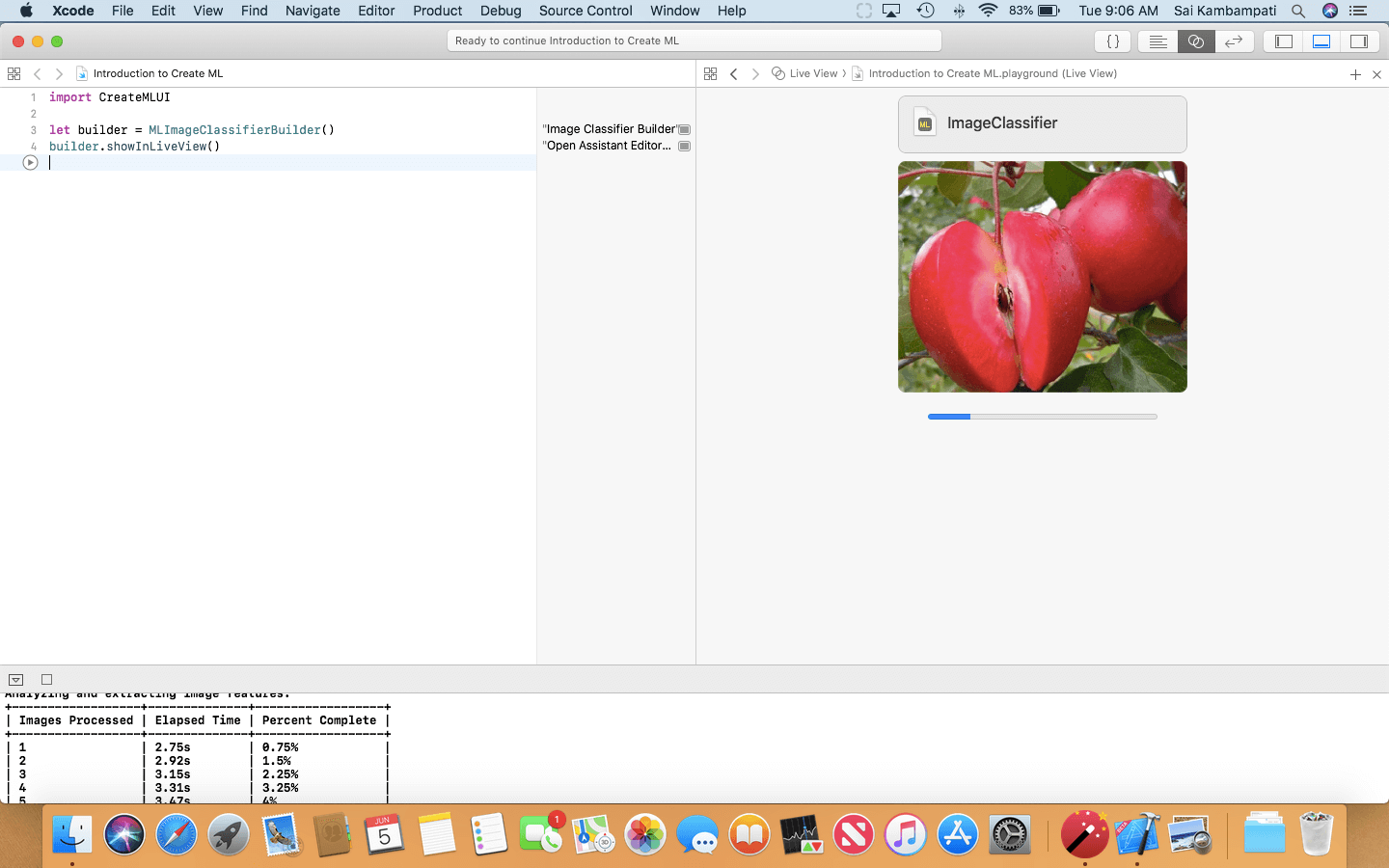
整個過程大約 30 秒(實際時間取決於你的設備)。當一切處理完成後,你應該會看到這個畫面:
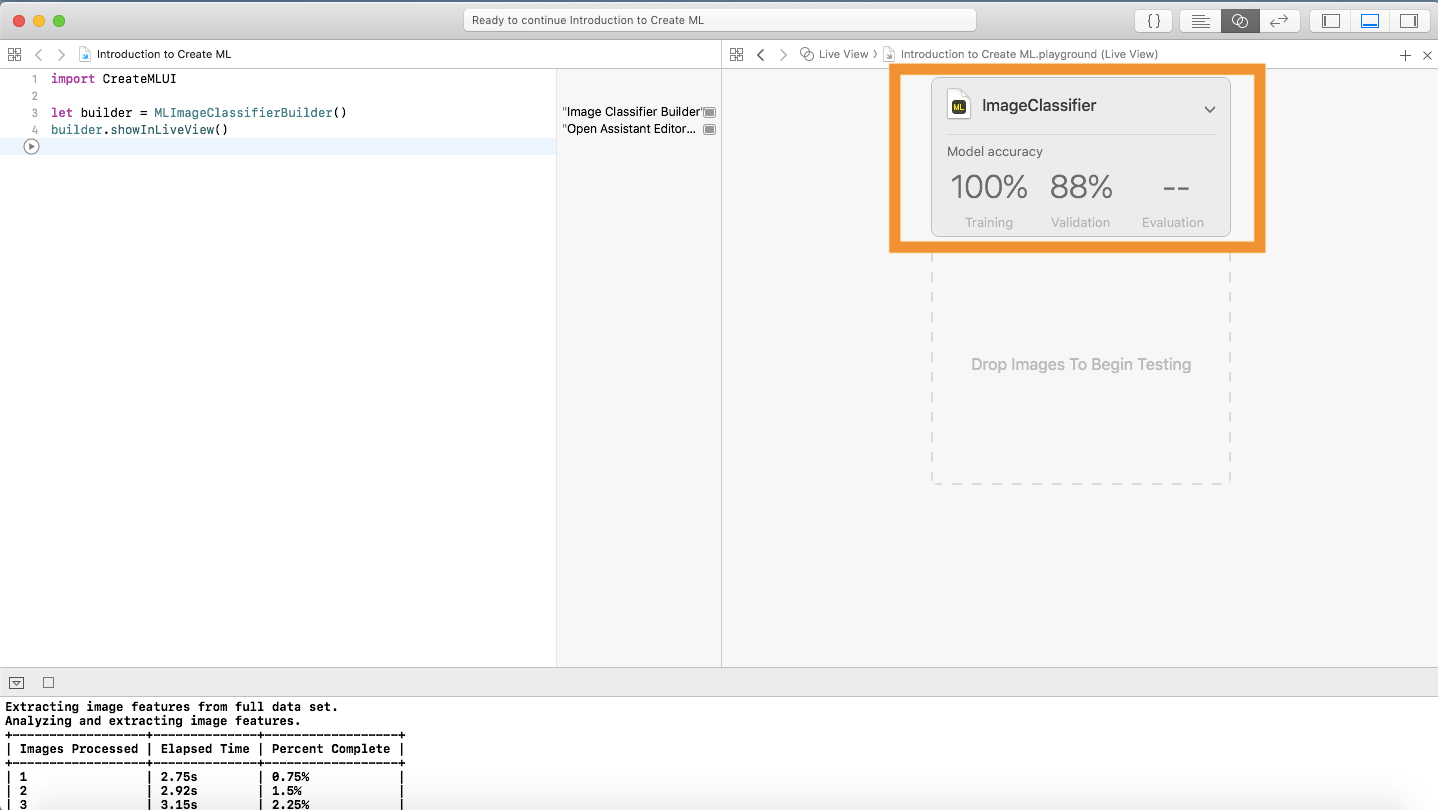
你會看到三個標籤:Training、Validation 和 Evaluation。Training 是指 Xcode 成功訓練數據的百分比,這應該是 100%。
訓練時,Xcode 將訓練數據分配為 80-20。在訓練了 80% 的訓練數據之後,Xcode 在剩下的 20% 上運行分類器,這就是 Validation 的意思:分類器能夠正確分類訓練圖像的百分比。通常來說,這百分比每次都不一樣,因為 Xcode 未必每次都分配出相同的數據。在我的例子中,Xcode 的 Validation 有 88%,並不需要擔心其準確率。Evaluation 則是空的,因為我們還沒有給測試數據予分類器。現在就來放測試數據吧!
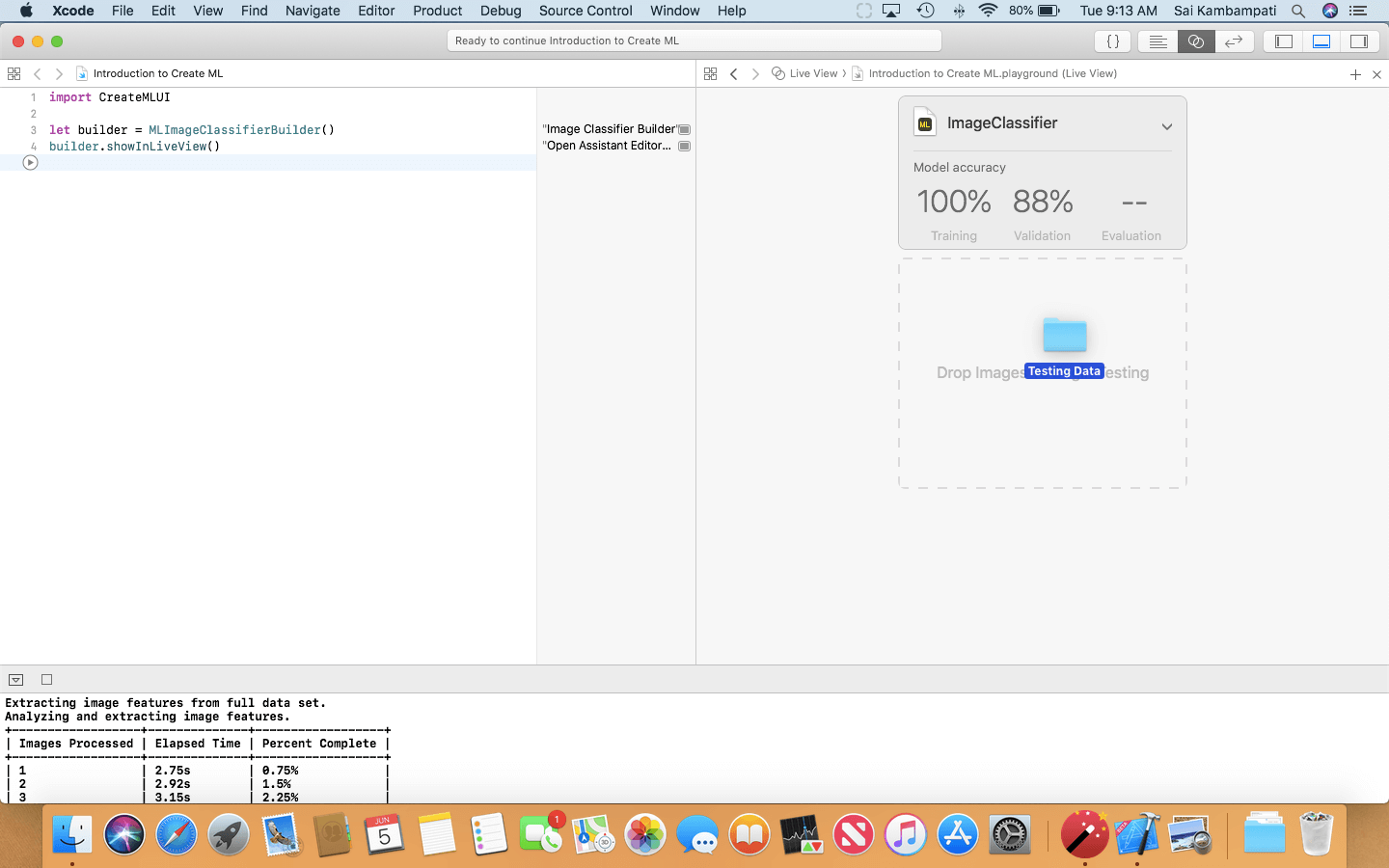
這應該很快完成,完成後,Evaluation 應該會是 100%,這意味著分類器正確標記了所有圖像!
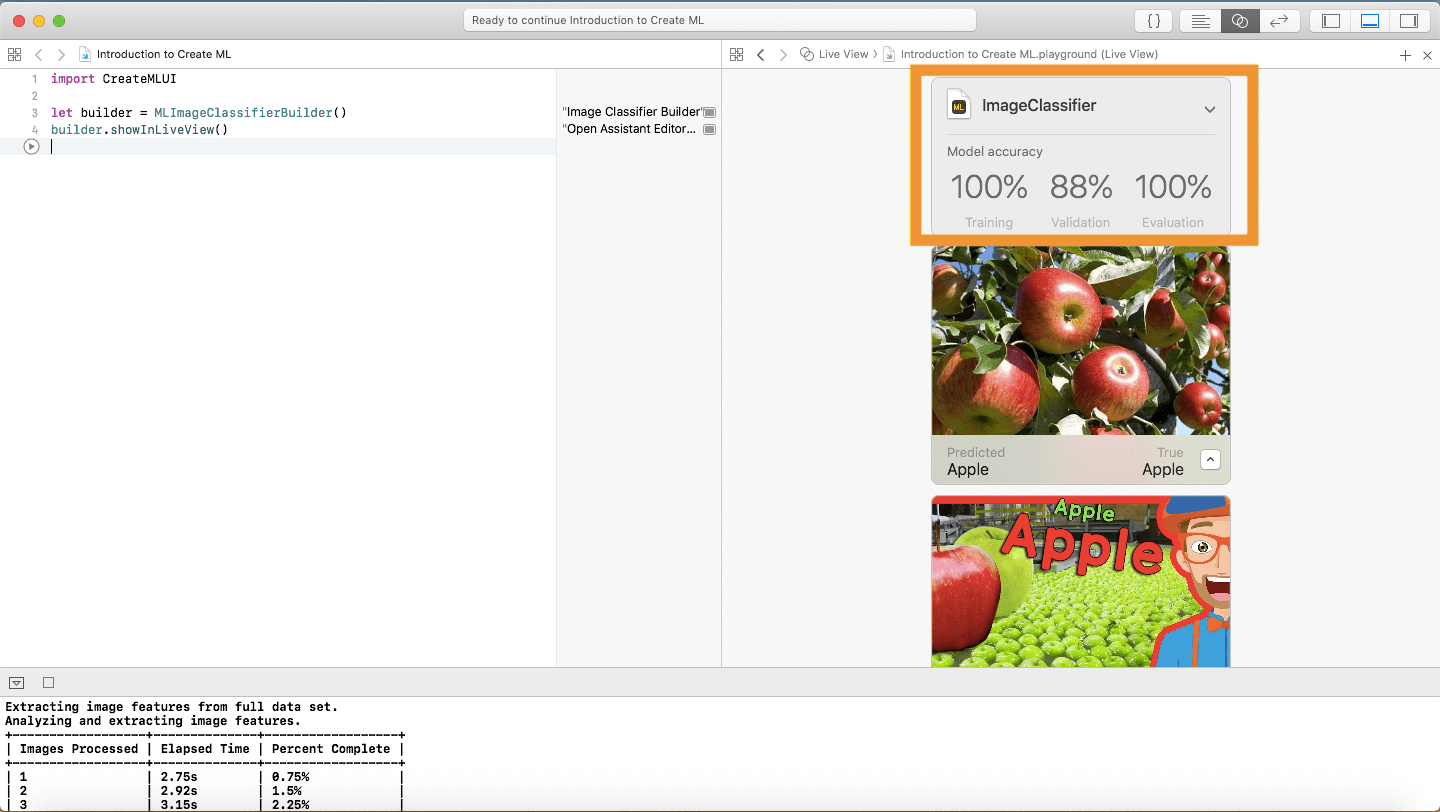
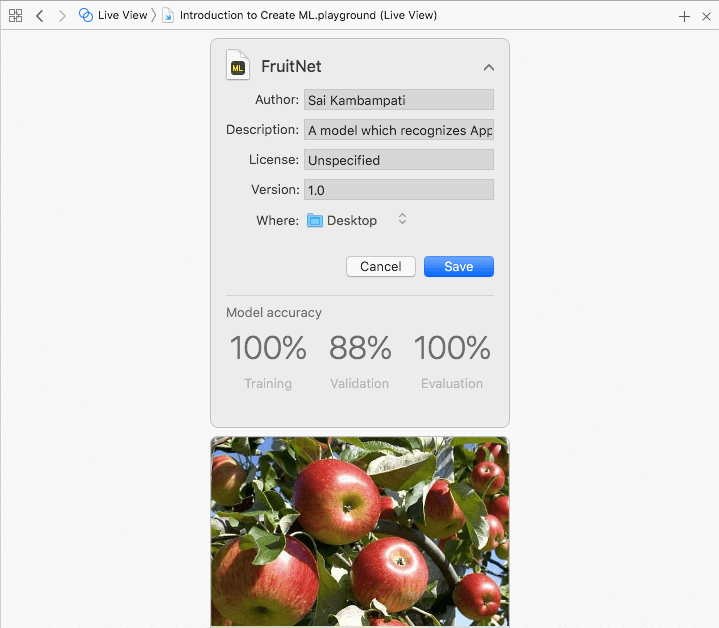
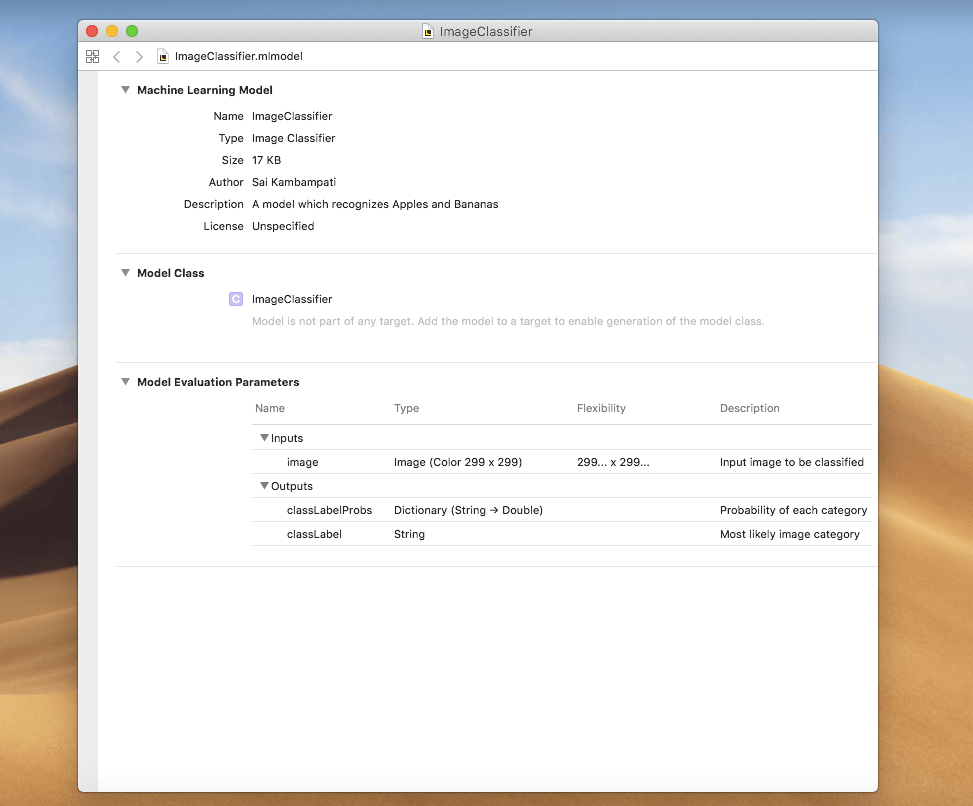
如果你對結果感到滿意,就可以存檔了!點擊 Image Classifier 旁邊的箭頭,下拉選單會顯示所有的元數據,填好元數據後就可以保存到任何位置!
打開 CoreML 模型並查看元數據,它已包含了你填寫的所有資料。恭喜你!你就是這個強大圖像分類器模型的作者,而且它只佔 17 KB!
你可以將它導入你的 iOS App,並檢查它的運作!接下來,我們來看看如何創建自己的文字分類器吧!這將會需要更多程式碼。
文字分類器模型
數據
接下來,我們將使用 Create ML 構建垃圾郵件檢測器模型,這個模型可以確定郵件是不是垃圾郵件。就如所有機器學習應用程式一樣,我們需要一些數據。請在這裡下載範例 JSON 文件。
打開文件後,你會看到一個包含大量資訊的 JSON 表格,列出這些資訊是不是垃圾郵件。與你的應用程式需要的數據相比,此範例數據量非常少。
程式碼
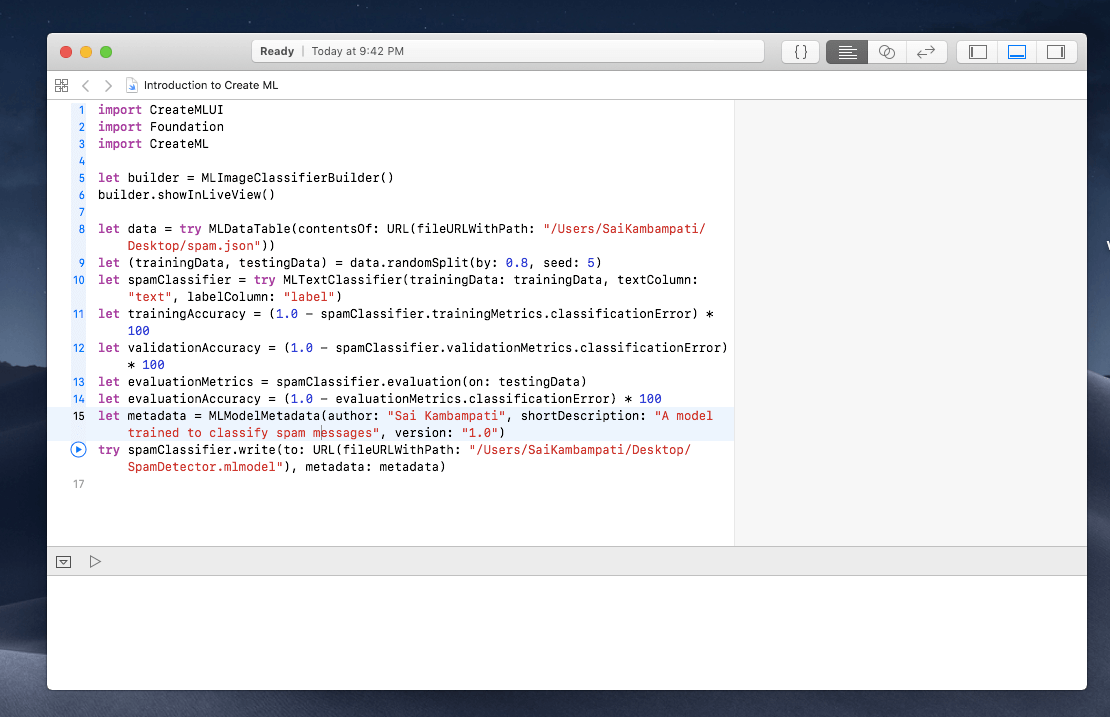
現在,我們必須指示 Xcode 訓練數據。雖然沒有一個漂亮又簡單的用戶界面,但我們所使用的程式碼並不困難。請輸入以下內容:
import CreateML
import Foundation
//1
let data = try MLDataTable(contentsOf: URL(fileURLWithPath: "/Users/Path/To/spam.json"))
let (trainingData, testingData) = data.randomSplit(by: 0.8, seed: 5)
let spamClassifier = try MLTextClassifier(trainingData: trainingData, textColumn: "text", labelColumn: "label")
//2
let trainingAccuracy = (1.0 - spamClassifier.trainingMetrics.classificationError) * 100
let validationAccuracy = (1.0 - spamClassifier.validationMetrics.classificationError) * 100
//3
let evaluationMetrics = spamClassifier.evaluation(on: testingData)
let evaluationAccuracy = (1.0 - evaluationMetrics.classificationError) * 100
//4
let metadata = MLModelMetadata(author: "Sai Kambampati", shortDescription: "A model trained to classify spam messages", version: "1.0")
try spamClassifier.write(to: URL(fileURLWithPath: "/Users/Path/To/Save/SpamDetector.mlmodel"), metadata: metadata)
讓我來解釋一下程式碼,大部分都應該相當簡單:
- 首先,我們在
spam.json檔案內創建型別為MLDataTable的常數data。MLDataTable是一個全新的物件,用於創建表格來訓練或評估 ML 模型。我們將數據分成trainingData和testingData,和前文一樣,比例為 80-20,Seed 為 5(Seed 是指分類器應從何處開始)。然後我們用訓練數據定義一個名為spamClassifier的MLTextClassifier,定義數據的甚麼數值是文本、甚麼數值是標籤。 - 我們創建了兩個變數
trainingAccuracy和validationAccuracy,用於確定分類器的準確率。在側面控制板中,你將能夠看到準確率的百分比。 - 我們也檢查了 Evaluation 的表現。(請記住,Evaluation 是分類器分類未接觸過的文字的準確度。)
- 最後,我們為 ML 模型創建一些元數據給作者、描述和版本等。我們使用
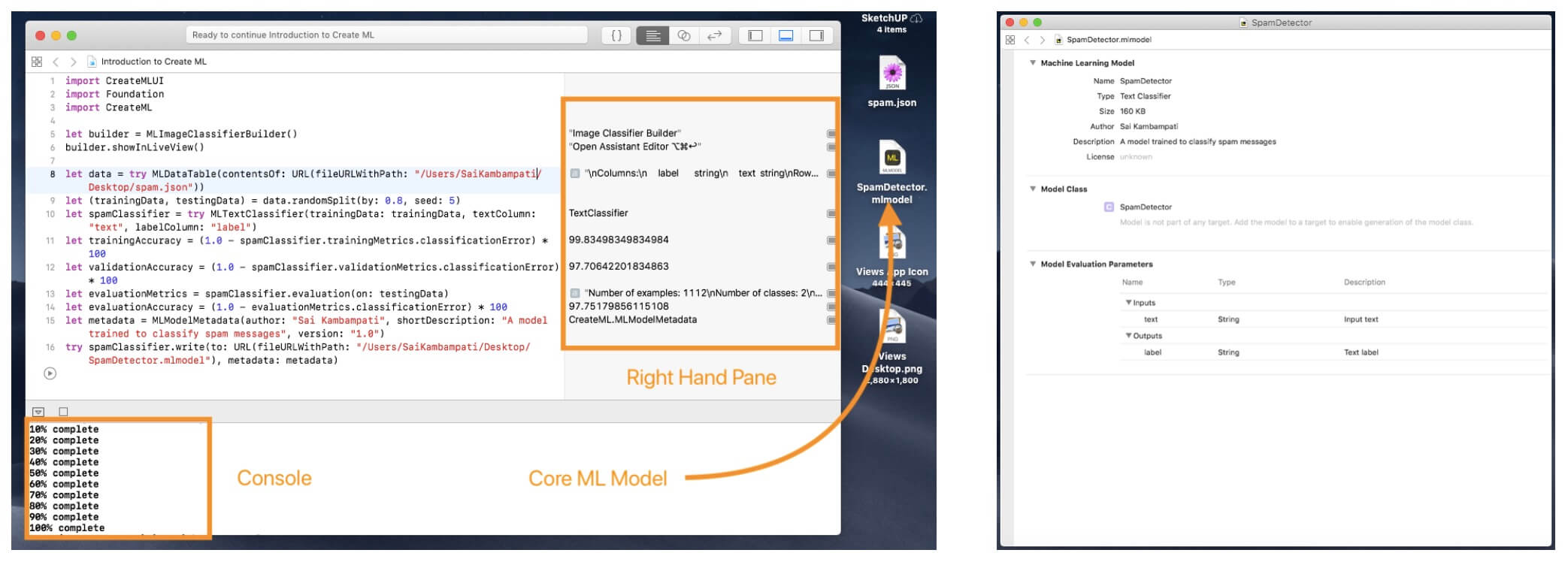
write()函數,將模型保存到我們選擇的位置!在下面的圖片中,你會看到我選擇了保存到桌面。
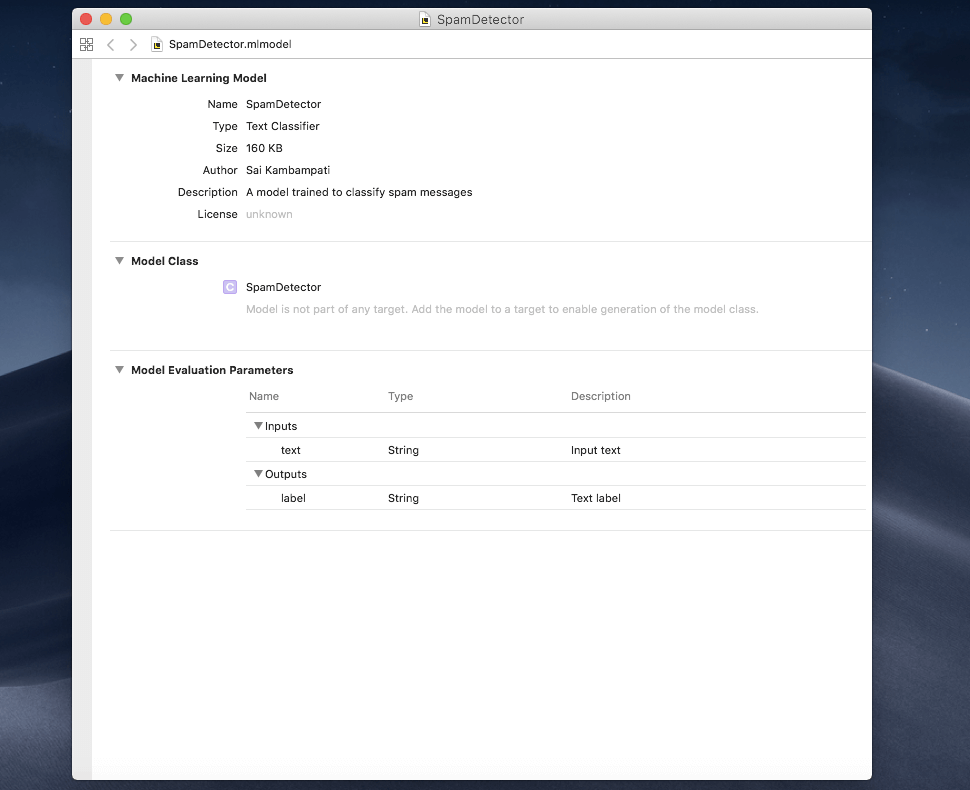
執行 Playground,你可以在控制台中查看疊代、右邊欄位查看準確度。全部完成後,Core ML 模型將被保存,你可以查看模型和元數據!
表格分類器
數據
表格數據是 Create ML 最先進和有趣的功能。通過觀察表格中的一組特徵,Create ML 可以檢測當中的規律,並創建分類器來檢測所需的目標特徵。
在這種情況下,讓我們來處理機器學習世界中最受歡迎的數據集 ── 房地產價格!為了令教程更有趣,數據集不是 JSON 格式,而是 CSV 格式!請在這裡下載數據集。
數據集是在 UCI 機器學習資料庫中,波士頓房地產資料的修訂版。打開文件,你會看到一個巨大的表格,裡面有數字和 4 個縮寫。以下是它們的意思:
- RM:每宅房間的平均數
- LSTAT:被認為是較低階層的人口比率
- PTRATIO:城內教師與學生的比率
- MEDV:自住房屋價格的中位數
你應該可以猜到,我們將使用 3 個特徵(RM、LSTAT、PTRATIO)來計算最終價格(MEDV)!
程式碼
讓 Xcode 讀取表格非常簡單,以下程式碼看起來應該與文字分類程式碼非常相似:
//1
let houseData = try MLDataTable(contentsOf: URL(fileURLWithPath: "/Users/Path/To/HouseData.csv"))
let (trainingCSVData, testCSVData) = houseData.randomSplit(by: 0.8, seed: 0)
//2
let pricer = try MLRegressor(trainingData: houseData, targetColumn: "MEDV")
//3
let csvMetadata = MLModelMetadata(author: "Sai Kambampati", shortDescription: "A model used to determine the price of a house based on some features.", version: "1.0")
try pricer.write(to: URL(fileURLWithPath: "/Users/Path/To/Write/HousePricer.mlmodel"), metadata: csvMetadata)
如果你不能理解上面的程式碼,沒關係,讓我們一步一步來!
- 第一步,我們呼叫
URL(fileURLWithPath:),以在HouseData.csv中引用我們的數據。然後,我們定義分配訓練數據和測試數據的比率,我們會像往常一樣分成 80-20,但我們會改變一點,就是讓分類器從頭開始分類(將seed設置為 0)。 - 接下來,我們使用全新的 MLRegressor 列舉,為數據定義
pricer迴歸器。這就是 Create ML 最酷的地方! ML 演算法有許多迴歸器可以使用,包括線性(Linear)、提升樹(Boosted Tree)、決策樹(Decision Tree)和隨機森林(Random Forest)等,這些只是最常見的幾個,但如果不是 ML 專家,就很難確定哪一種最適合你的數據,這時 Create ML 就可以幫到你了。當你選擇MLRegressor時,Create ML 會利用所有迴歸器運行你的數據,並為你選擇最適合的迴歸器。我們選擇訓練數據為houseData,並將目標列設置為MEDV,也就是房屋價格中位數。這裡容我快速介紹一些術語。分類器和迴歸器之間有什麼區別呢?分類器將數據的輸出分為到類別或標籤;而迴歸器不會有標籤,它使用訓練數據預測輸出值。另外,在機器學習中,特徵是數據集的變量。在我們的例子中,特徵就是房間的平均數量、人口的百分比、和師生比例;而目標是數據中的其中一列,列出想要迴歸器預測的數據 ── 即是房屋價格中位數。
- 最後,我們為模型設定元數據,並保存到任何地方!
在撰寫本文時,Create ML 還未支援顯示 MLRegressors 的準確度,它只能顯示最大誤差和平方根誤差,兩者對顯示模型的準確度沒什麼用。不過相信我吧,Xcode 開發的模型是相當準確的。
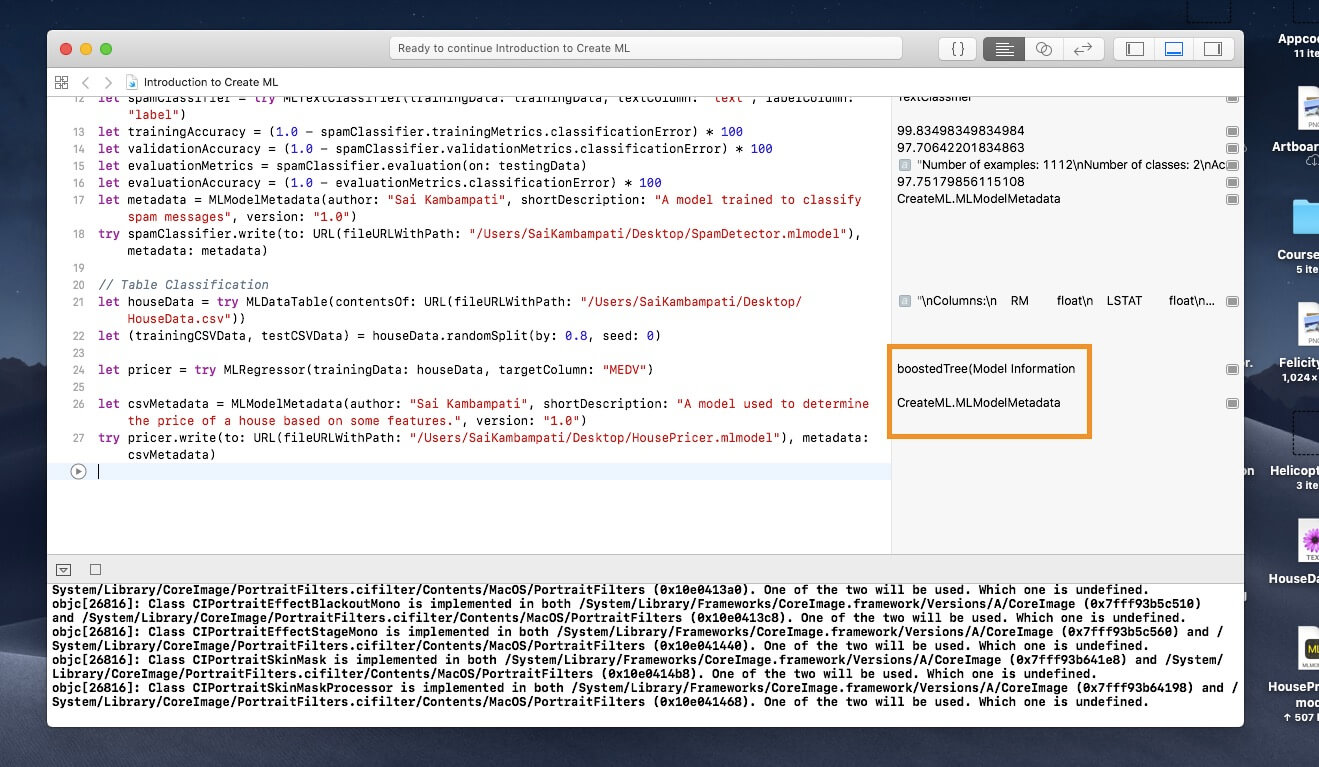
在 Playground 執行完成後,請看看右邊欄位,Create ML 已經確定 Boosted Tree 迴歸器最適合我們的數據!是不是很神奇?我已將 Core ML 模型保存到我的桌面,請打開 Core ML 模型並查看元數據。

結語
在本教學中,你學懂了如何使用 Apple 最新框架 Create ML 創建自己的機器學習模型!只需幾行程式碼,你就可以創建先進的機器學習演算法來處理數據,並提供所需結果!
你學懂如何訓練 CSV 和 JSON 格式的圖像、文字和表格數據。使用 CreateMLUI,圖像訓練非常簡單,而且用於沒有 UI 的文本和表格數據,所需程式碼更是少於 10 行。
若想要瞭解更多有關 Create ML 的資訊,你可以在 WWDC 2018 觀看 Apple 的相關視頻,你也可以在這裡查看 Apple 的相關文件。
你可以在這裡下載最後的 Playground。隨著這個專案,你可以得到最終的 Core ML 模型,以便查看你的模型是否匹配!繼續嘗試 Create ML,並在導入 iOS App 時觀察結果!歡迎在下面留言,分享你的進度和 App 的截圖!
原文:Introduction to Create ML: How to Train Your Own Machine Learning Model in Xcode 10