
作為一位自然語言處理實驗室畢業的研究生、目前專職撰寫原生行動應用程式的軟體工程師,今年 Apple 的 WWDC 有一項議程特別引起我的注意:「自然語言處理與你的應用程式」(Natural Language Processing and your Apps)。我的所學(講的好像我真的會自然語言處理一樣)跟我的工作(講的一副我真的會寫 App 的樣子)終於產生連結了嗎?
所以趁著公司被賣掉的週末就把影片開來配飯吃,順便試著玩玩看這次新開放(這我倒是不太確定了,從文件來看部分 APIs 早在今年才要推出的 iOS 11 之前就已經支援)的自然語言處理 APIs,加減練習一下我越看越覺得好看的 Swift。
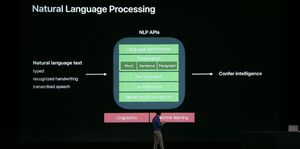
自然語言處理流程
這段 WWDC 的議程首先介紹了大致的自然語言處理流程,首先當然是要有要被處理的文本,可能透過鍵盤打字輸入、手寫輸入或語音輸入辨識之後得到一段文字。
再來可能要先辨識這段語言是哪一個語言,是英文、中文還是克林貢語?
知道語言之後根據語言的特性,拿勝利寶劍🗡來斷開魂結,這一步叫做斷詞(Tokenization),把一個文本斷成一些基本的段落,像是一個個詞彙。例如把「你猜我一共環遊世界幾次?」斷成「你」、「猜」、「我」、「一共」、「環遊」、「世界」、「幾」、「次」這樣的單字單位。英文在這個問題上相對簡單很多,因為英文的字與字中間是用空白隔開的,但中文字全都連在一起,於是有各式各樣的斷詞方法。
斷詞之後為了進行後續的應用,我們也許也會想要知道每個詞的詞性,所以有一步叫做詞性標注(POS, Part of Speech),例如剛剛那句話裡面的「環遊」是動詞。
在某些語言之中的動詞或名詞會有不同的表現形式,像是動詞時態、名詞單複數型等等,經過一陣努力的斷詞處理之後,或許需要知道原來「playing」、「plays」都是「play」 的變化,其實是同一個或者說是極為近似的概念;「cats」跟「cat」是指涉同一種動物等等。所以會有一個詞形還原(Lemmatization)的步驟。
經過上述處理之後,我們也可能需要知道是不是有些詞是地名、人名、組織名稱之類的以利後續利用,所以需要具名實體辨識(NER, Named Entity Recognition)。像是偵測出「滿滿的大平台」的「大平台」是一個位在日本箱根的地名。(這個例子是亂寫的)
所以在一陣猛烈的自然語言處理之後我們就可以把原本的文本輸入弄成一堆帶有各式各樣標記的詞彙甚至弄出一個句子的樹狀結構,再來就可以直接利用或者拿去一陣猛烈的機器學習去理解語意了。
在 iOS 應用程式裡進行自然語言處理
為了讓 App 可以方便地進行自然語言處理,Apple 這次提供給開發者一組方便的自然語言處理 APIs,目前看來主要是 NSLinguisticTagger 這個物件。(我猜他們應該之前就有類似的內部 APIs 了,畢竟 Siri 也推出這麼多年了,或許是搭著 CoreML 一起把自然語言處理的 APIs 放出來讓大家玩玩)
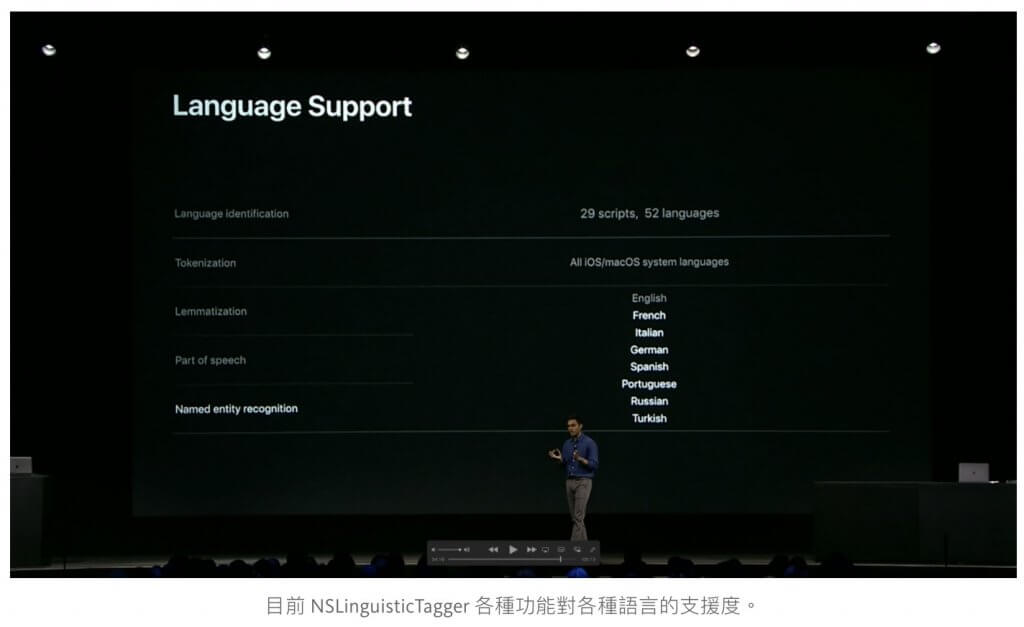
以目前最新的文件來看,NSLinguisticTagger 支援下列功能:
- 語言辨識
- 斷詞
- 詞性標記
- 詞形還原
- 具名實體辨識
目前詞性標記、詞形還原跟具名實體辨識根據投影片上的介紹只支援了英文、法文、義大利文、德文、西班牙文、葡萄牙文、俄文、土耳其文。
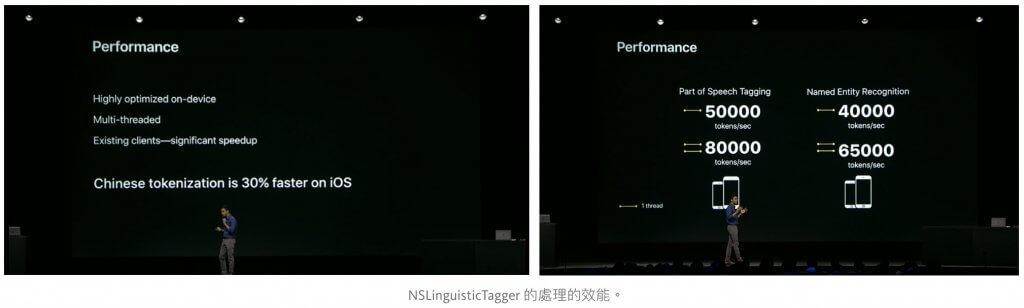
效能上,蘋果強調這是針對機器最佳化的、可多執行緒處理,由於是在機器上獨立運作的,因此蘋果也說這是很有隱私的。
在 WWDC 的影片中分別示範了兩個應用,一個是利用斷詞與詞形還原讓搜尋可以透過單字比對直接找到帶有文字描述的照片,而另外則是應用具名實體辨識來分類社群貼文。
使用 NSLinguisticTagger
參考這次議程的投影片跟文件,我用 Swift 4.0 在 Xcode 9.0 Beta 的 Playground 小試了一下 NSLinguisticTagger 的各種應用。
在 Swift 4.0 / iOS 11+ 環境下,NSLinguisticTagger 有了一個新的建構子,將原先帶入的 tag 字串改成新的 structure NSLinguisticTagScheme,裡面幾個常數大概就是用來指定下列各種用途。
語言辨識
func languageTest(sentence: String) {
let tagger = NSLinguisticTagger(tagSchemes: [.language], options: 0)
tagger.string = sentence
if let language = tagger.dominantLanguage {
print("\(language)")
} else {
print("Unknow.")
}
}
用 NSLinguisticTagScheme.language 作為參數來初始化 NSLinguisticTagger,將欲判定語言的字串放入 tagger 的 string 後,取用 dominantLanguage 取得字串的語言類別,回傳的語言類別是符合 BCP 47 規範的語言字串,像是正體中文會回傳 zh-Hant,英文回傳 en。從文件上看來這個問語言的功能應該是這次新增的。
languageTest(sentence: "我們現在談的不是五十萬,是五百萬!") // "zh-Hant" languageTest(sentence: "We are not talking about five hundred thousand, is five million!") // "en" languageTest(sentence: "社会のセグメントは、その職務を遂行します") // "ja"
斷詞
幾乎是中文語言處理必定要面對的問題,以前小時候在研究室的時候會用史丹佛大學的 Stanford Parser,古早年代 Yahoo 還有一個 API 叫做斷章取義,但後來收掉了。聽說現在的小朋友用結巴的比較多。當然我覺得中央研究院的 CKIP 也不錯,就是操作介面難用了些。 (其實忘了 NLTK 是不是應該也能做中文斷詞)
現在有了新的選擇(好吧從文件看是 2012 年就有了,這是我進實驗室的那一年,為什麼我都不知道有這東西😭)NSLinguisticTagger。初始化帶入的 tag scheme 是 tokenType,一樣透過 tagger 的 string 把要斷的字串塞進去,使用 enumerateTags(in:unit:scheme:options:using:) 來拿結果。
func tokenize(sentence: String) -> [String] {
var tokens:[String] = [String]()
let tagger = NSLinguisticTagger(tagSchemes: [.tokenType], options: 0)
tagger.string = sentence
let range = NSMakeRange(0, sentence.utf16.count)
let options: NSLinguisticTagger.Options = [.omitWhitespace, .omitPunctuation]
tagger.enumerateTags(in: range, unit: .word, scheme: .tokenType, options: options) { (tag, tokenRange, stop) in
let word = (sentence as NSString).substring(with: tokenRange)
tokens.append(word)
}
return tokens
}
這邊先設定選項,去掉標點符號(.omitPunctuation)跟空白(.omitWhitespace)。告訴 tagger 我要的單位是字(其他還可以填文章、段落、句子,請參閱這裡看更多單位),幫我做斷詞(scheme: .tokenType)。
結果就會拿到 token 在原先句子裡頭的範圍,就可以當成斷詞之後的結果。看起來還行還行。
let texts: [String] = ["你猜我一共環遊世界幾次?",
"qcl誠徵女友",
"我想交個女朋友"]
for text in texts {
let tokens = tokenize(sentence: text)
print("\(text) --> \(tokens)")
}
// Output:
// 你猜我一共環遊世界幾次? --> ["你", "猜", "我", "一共", "環遊", "世界", "幾", "次"]
// qcl誠徵女友 --> ["qcl", "誠徵", "女友"]
// 我想交個女朋友 --> ["我", "想", "交", "個", "女朋友"]
詞性標記
一樣繼續使用 NSLinguisticTagger,tag scheme 用 lexicalClass。跟斷詞一樣,給定範圍與選項,使用 enumerateTags 來取得結果。不囉唆直接上程式碼:
func POS(sentence: String) {
let tagger = NSLinguisticTagger(tagSchemes: [.lexicalClass], options: 0)
tagger.string = sentence
let range = NSMakeRange(0, sentence.utf16.count)
let options: NSLinguisticTagger.Options = [.omitWhitespace, .omitPunctuation]
tagger.enumerateTags(in: range, unit: .word, scheme: .lexicalClass, options: options) { (tag, tokenRange, stop) in
let word = (sentence as NSString).substring(with: tokenRange)
if let tag = tag {
print("\(word) : \(tag.rawValue)")
}
}
}
上面的範例程式直接把詞性的字串印出來,實際使用上建議還是使用 NSLinguisticTag 的常數,像是 NSLinguisticTag.noun 當名詞來使用這樣。詳細的詞性列表請按這裡看更多。
POS(sentence: "qcl wants a girlfriend.") // Output: // qcl : Pronoun // wants : Verb // a : Determiner // girlfriend : Noun
詞形還原
繼續使用 NSLinguisticTagger,使用 lemma 作為 tag scheme。剩下基本上就都跟斷詞一樣了,用 enumerateTags 來拿結果。一樣直接看程式碼:
func lemmatize(sentence: String) {
let tagger = NSLinguisticTagger(tagSchemes: [.lemma], options: 0)
tagger.string = sentence
let range = NSMakeRange(0, sentence.utf16.count)
let options: NSLinguisticTagger.Options = [.omitWhitespace, .omitPunctuation]
tagger.enumerateTags(in: range, unit: .word, scheme: .lemma, options: options) { (tag, tokenRange, stop) in
let word = (sentence as NSString).substring(with: tokenRange)
if let lemma = tag?.rawValue {
print("\(word) -> \(lemma)")
} else {
print("\(word) -> ???")
}
}
}
在這裡文件的描述是會回傳「A stem of the word, if available」,就是如果有詞幹的話就回傳,不然就沒有。所以可以看到拿 tag 的地方,會先看有沒有 rawValue 再把它拿出來。
lemmatize(sentence: "qcl wants a girlfriend.") // Output // qcl -> ??? // wants -> want // a -> a // girlfriend -> girlfriend
具名實體辨識
基本上呢,跟前面的都一樣使用 NSLinguisticTagger(寫到這裡 Linguistic 這個字也該背起來了),tag scheme 是 nameType。當然也跟先前都一樣,使用 enumerateTags 來取得結果。
func NER(sentence: String) {
let tagger = NSLinguisticTagger(tagSchemes: [.nameType], options: 0)
tagger.string = sentence
let range = NSMakeRange(0, sentence.utf16.count)
let options: NSLinguisticTagger.Options = [.omitWhitespace, .omitPunctuation, .joinNames]
let tags: [NSLinguisticTag] = [.personalName, .placeName, .organizationName]
tagger.enumerateTags(in: range, unit: .word, scheme: .nameType, options: options) { (tag, tokenRange, stop) in
if let tag = tag, tags.contains(tag) {
let name = (sentence as NSString).substring(with: tokenRange)
print("\(name) is \(tag.rawValue)")
}
}
}
在這裡的選項多加了一個 NSLinguisticTagger.Options.joinNames,文件的描述是說通常多個字會被當成多個 token 回傳,如果家了這個選項可以讓多字組成的名字當成一個 token 被辨識。
nameType 透過 enumerateTags 拿回的 NSLinguisticTag 目前有三種,分別是人名(.personalName)、地名(.placeName)與組織名(.organizationName)。範例程式裡確認 tag 是這三種才把被辨識到的具名實體及其類別一起印出來。
NER(sentence: "Taiwan is an independent country, not a part of China.") // Output: // Taiwan is PlaceName // China is PlaceName NER(sentence: "Taiwan is not a part of People's Republic of China.") // Output: // Taiwan is PlaceName // China is PlaceName NER(sentence: "Republic of China and People's Republic of China are two counties.") // Output: // China is PlaceName // People's Republic of China is OrganizationName NER(sentence: "Ohiradai is located in Japan.") // Output: // Japan is PlaceName NER(sentence: "Marissa Mayer was the CEO of Yahoo.") // Output: // Marissa Mayer is PersonalName // Yahoo is OrganizationName
在前三個例子之中,第一句「臺灣是一個獨立國家,不是中國的一部分」,它辨識到「臺灣」和「中國」是兩個地名;第二句「臺灣不是中華人民共和國的一部分」,一樣辨認到「臺灣」是地名,但沒有辨識出「中華人民共和國」🇨🇳作為一個組織,只認到「中國」當作地名;第三句「中華民國和中華人名共和國是兩個國家」中,中華民國裡的「中國」被當作地名辨識,而「中華人民共和國」🇨🇳卻作為一個組織完整地出現。算是蠻有意思的結果。
第四句「大平台位在日本」中,NSLinguisticTagger 並未認出「大平台」,只認出了「日本」🇯🇵作為一個地名。
最後一句「Marissa Mayer 是 Yahoo 的 CEO」認出了梅姐的名字以及 Yahoo 作為組織名稱。
我猜大概因為是本地離線的辨識模型,這種(不失一般性)需要靠字典的應該就是本地有個辭典可以查,所以效果應該有某種程度的辨識,或者本地有個已經訓練好的模型可以幫助判斷吧,但畢竟還是需要辭典的。前三組的結果讓我感覺也不盡然只靠查辭典,真的有點意思。
結語
以上簡單嘗試了 NSLinguistTagger 支援的自然語言處理功能:語言辨識、斷詞、詞性標記、詞形還原與具名實體辨識。今年另外一場 WWDC 的議程「Core ML in depth」中有進一步結合 Core ML 與 NSLinguistTagger 的應用,之後如果有空應該會把那場拿來再寫一篇。