

Apple 在 WWDC 2020(線上版)開發者大會中響起了平地一聲雷,釋出了許多讓人驚喜的新功能,(延伸閱讀:Apple’s own silicon chips for Macs),包括 SwiftUI、ARKit、PencilKit、Create ML 還有 Core ML。但是其中,對我來說最突出的是電腦視覺處理 (computer vision)。
Apple 推出了一系列新 API 之後,Vision 框架得到了更完善的支援。這些新 API 提供了一個更直接的方式,來執行複雜且重要的電腦視覺處理演算法。
從 iOS 14 開始,Vision 框架支援手部及身體的姿勢估計 (Hand and Body Pose Estimation)、光流 (Optical Flow)、軌跡偵測 (Trajectory Detection)、以及輪廓偵測 (Contour Detection)。
現在,先讓我們看看其中一個有趣的新功能 ── 視覺輪廓偵測 (Vision Contour Detection) 吧。
目標
- 了解 Vision 的輪廓偵測請求。
- 在 iOS 14 SwiftUI App 執行一個輪廓偵測請求,來偵測硬幣的輪廓。
- 把圖像傳遞給 Vision 請求之前,先利用 Core Image 濾鏡對圖像進行前處理(pre-process) 來簡化輪廓。我們會嘗試在圖像加上遮罩來降低材質的雜訊,讓輪廓顯得更清楚。
視覺輪廓偵測 (Vision Contour Detection)
輪廓偵測的做法,是偵測圖像邊緣的形狀。實務上來說,它會連接所有相同顏色跟密度的連續點,來組成完整的輪廓。
這個電腦視覺處理功能,非常適用於形狀分析、邊緣偵測,而且如果需要從一張圖像裡面,找到相似形狀物件的情況下,這個功能就非常有用。
硬幣偵測與分割這項處理在 OpenCV 非常常見,現在我們使用 Vision 框架新的 VNDetectContoursRequest,就可以輕易地在 iOS App 裡執行一樣的功能(不需要第三方套件)。
要處理圖像或畫面,Vision 框架需要將 VNRequest 傳給圖像請求處理器 (image request handler),或連續請求處理器 (sequence request handler),然後我們會得到一個回傳的 VNObservation 類別。
你可以依照執行的請求型別,來決定使用哪個 VNObservation 子類別。在我們這個範例中,我們將使用 VNContoursObservation 來取得所有在圖像中偵測到的輪廓。
我們可以從 VNContoursObservation 查看下列各個參數:
normalizedPath:它會以標準化座標回傳偵測到的輪廓路徑,我們需要將這個座標轉成 UIKit 的座標,我們在下文將會再說明這一點。contourCount:這是透過視覺請求 (Vision request) 所偵測到的輪廓數量。topLevelContours:這是未包含在任何輪廓內的VNContours陣列 。contour(at:):透過這個方法,我們可以傳入其索引值或IndexPath,來取得一個子輪廓。confidence:這是整個VNContoursObservation的信心程度。
請注意:利用
topLevelContours以及存取子輪廓等方法,可以讓我們很方便地從最後的觀測結果中修改/移除子輪廓。
現在,初步了解了視覺輪廓偵測的請求後,讓我們來看看如何在 iOS 14 的 App 上執行吧!
開始動手
在開始之前,你最少要有 Xcode 12 beta 版本,如此一來,你就可以在 SwiftUI Previews 中直接執行視覺圖像請求 (Vision image request)。
利用 Xcode Wizard 建立一個新的 SwiftUI App,你會看到新的 SwiftUI App 的 Life Cycle:
完成專案建置之後,你會得到下列的程式碼:
@main
struct iOS14VisionContourDetection: App {
var body: some Scene {
WindowGroup {
ContentView()
}
}
}請注意:從 iOS 14 開始,
SceneDelegate在 SwiftUI 的Appprotocol 已經是過時的用法了,特別是在使用 SwiftUI 為基礎的 App。現在已經改成在struct的上面加上了@main註釋,來表明是 App 的進入點。
使用視覺輪廓請求來偵測硬幣
讓我們快速建立一個 SwiftUI 視圖,來執行視覺請求:
struct ContentView: View {
@State var points : String = ""
@State var preProcessImage: UIImage?
@State var contouredImage: UIImage?
var body: some View {
VStack{
Text("Contours: \(points)")
Image("coins")
.resizable()
.scaledToFit()
if let image = preProcessImage{
Image(uiImage: image)
.resizable()
.scaledToFit()
}
if let image = contouredImage{
Image(uiImage: image)
.resizable()
.scaledToFit()
}
Button("Detect Contours", action: {
detectVisionContours()
})
}
}
func detectVisionContours(){
//TODO:
}
}在上面的程式碼中,我們使用了 SwiftUI 在 iOS 14 才開放的新語法 if let。讓我們先忽略 preprocessImage 這個狀態物件;現在先來看看 detectVisionContoursss 這個函數,它會依照視覺請求的結果來更新 outputImage。
func detectVisionContours(){
let context = CIContext()
if let sourceImage = UIImage.init(named: "coin")
{
var inputImage = CIImage.init(cgImage: sourceImage.cgImage!)
let contourRequest = VNDetectContoursRequest.init()
contourRequest.revision = VNDetectContourRequestRevision1
contourRequest.contrastAdjustment = 1.0
contourRequest.detectDarkOnLight = true
contourRequest.maximumImageDimension = 512
let requestHandler = VNImageRequestHandler.init(ciImage: inputImage, options: [:])
try! requestHandler.perform([contourRequest])
let contoursObservation = contourRequest.results?.first as! VNContoursObservation
self.points = String(contoursObservation.contourCount)
self.contouredImage = drawContours(contoursObservation: contoursObservation, sourceImage: sourceImage.cgImage!)
} else {
self.points = "Could not load image"
}
}從上面的程式碼中,我們已經在 VNDetectContoursRequest 當中設定了 contrastAdjustment (以加強影像)、以及 detectDarkOnLight (以在明亮的背景上更好地進行輪廓偵測)這兩個參數。
執行 VNImageRequestsHandler 並且傳入一個圖像後(存在 Assets 資料夾中),我們會得到一個 VNContoursObservation。
最後,我們在傳入的影像上畫出 normalizedPoints 圖層。
在圖像上畫出輪廓
以下是 drawContours 函數的程式碼:
public func drawContours(contoursObservation: VNContoursObservation, sourceImage: CGImage) -> UIImage {
let size = CGSize(width: sourceImage.width, height: sourceImage.height)
let renderer = UIGraphicsImageRenderer(size: size)
let renderedImage = renderer.image { (context) in
let renderingContext = context.cgContext
let flipVertical = CGAffineTransform(a: 1, b: 0, c: 0, d: -1, tx: 0, ty: size.height)
renderingContext.concatenate(flipVertical)
renderingContext.draw(sourceImage, in: CGRect(x: 0, y: 0, width: size.width, height: size.height))
renderingContext.scaleBy(x: size.width, y: size.height)
renderingContext.setLineWidth(5.0 / CGFloat(size.width))
let redUIColor = UIColor.red
renderingContext.setStrokeColor(redUIColor.cgColor)
renderingContext.addPath(contoursObservation.normalizedPath)
renderingContext.strokePath()
}
return renderedImage
}上述的程式碼會回傳一個 UIImage,我們把圖像設定給 contouredImage 這個 SwiftUI 狀態物件之後,畫面就會隨之更新:
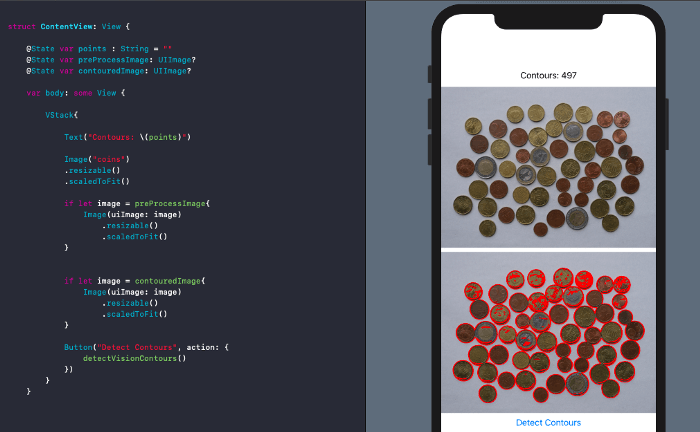
如果我們用模擬器來執行是的話,這個結果算是不錯,但是如果我們使用 iOS 14 裝置,有了手機的神經網路引擎 (Neural Engine),結果肯定會更好。
不過,這張圖上對我們而言有太多輪廓了(主要是因為硬幣的材質)。我們可以透過前處理,讓這張圖的輪廓更簡潔(又或是減少這些輪廓)。
使用 Core Image 來為視覺影像請求做前處理
Core Image 是 Apple 一個影像處理及分析的框架。雖然這個框架可以偵測簡單的面部和條形碼,但卻不適用於複雜的電腦視覺處理。
不過,這個框架有超過兩百個圖像濾鏡,在照片 App、或是機器學習模型訓練的資料增強上 (data augmentation) 使用起來也非常方便。
但更重要的是,要為傳給 Vision 框架做分析的圖像做前處理時,Core Image 就大派用場了。
如果你已經看過 WWDC 2020 電腦影像 APIs 的影片,就會看到在演示偵測打孔卡輪廓時,Apple 就利用了 Core Image 的 monochrome 濾鏡為圖像做前處理。
在我們的範例中,要在硬幣上遮罩,使用 monochrome 效果的結果不是很好。特別是對於硬幣這種顏色相似、但又跟背景顏色不同的情況,使用黑白色彩濾鏡會是更好的選擇。

對於上面所使用的前處理型別,我們也設定了高斯濾鏡 (Gaussian filter) 讓圖像更平滑。你可以注意到,使用 monochrome 前處理濾鏡,其實會讓我們得到更多的輪廓。
因此,在進行前處理時,一定要注意需要處理的圖像類型。
經過前處理後,我們把得到的 outputImage 傳給視覺影像請求。GitHub Repository 上有完整的原始碼,你可以在當中找到建立及套用 Core Image 濾鏡的程式碼片段。
分析輪廓
我們可以利用 VNGeometryUtils 類別,來觀察不同的參數,像是輪廓直徑、邊界圓 (Bounding Circle)、面積跟周長、以及長寬比例。我們只需要將要觀察的輪廓物件傳入:
VNGeometryUtils.boundingCircle(for: VNContour)就可以在一個圖像當中,分辨不同種類的形狀,這開啟了更多新電腦視覺處理的可能性。
更進一步,我們可以在 VNContour 中呼叫 polygonApproximation(withEpsilon:) 方法,將邊緣附近的小雜訊過濾掉來簡化輪廓。
結論
電腦視覺處理在 Apple 未來的混合實境中扮演非常重要的角色,引入了 ARKit 框架的手部和身體姿勢的 API 後,將為建立智慧電腦視覺處理 App 開啟新的可能性。
WWDC 2020 還有很多令人興奮的內容。對於在手機上有機器學習的新可能,我覺得非常興奮。敬請期待之後的更新,謝謝你的閱讀。