
Apple 為開發者社群做了很多事情的同時,亦有另一間公司費盡苦心創造好的工具和服務給開發者,這間公司就是 Google。近年,Google 致力推出並不斷改進他們的服務,像是 Google Cloud、Firebase、TensorFlow 等等,讓 iOS 與 Android 開發者的力量更強大。
在 Google I/O 2018 開發者大會上,Google 發表了一款全新的開發工具 ML Kit 給開發者。Google 在人工智能競爭上一直領先,這次讓開發者獲取 ML Kit 的模型,也代表著 Google 給予開發者很強大的力量。
有了 ML Kit,你只需要很少程式碼就可以執行各種機器學習任務。CoreML 與 ML Kit 最大的分別是,在 CoreML 你必須加入自己的模型,但在 ML Kit 你可以選擇 Google 所提供的模型或是執行自己的模型。在本次教學中,我們會選擇 Google 使用的模型,因為加入自己的模型必須使用 TensorFlow、並對 Python 有相當程度的瞭解。
編者提醒:經過 WWDC 18 的發表後,你現在可以藉由 Xcode 10 的 Playgrounds 使用 CreateML 來創建自己的 ML 模型。
另一點差異是,若你的模型很大,你必須有能力將 ML 模型放到 Firebase 之中,並讓你的 App 呼叫伺服器。在 CoreML,你只需要在設備上執行機器學習就可以了。而下列就是 ML Kit 的相關應用:
- 條碼掃描
- 人臉偵測
- 圖像標籤
- 文字辨識
- 地標辨識
- 智慧回覆(即將推出)
在本教學中,我將會展示如何在 Firebase 上創建一個新專案、使用 Cocoapods 下載必要的套件、並將 ML Kit 整合到我們的 App 之中!讓我們開始吧!
創建一個 Firebase 專案
第一步,先到 Firebase 控制台,然後登入你的 Google 帳戶,完成登入後你應該會看到以下的歡迎畫面。

按下 Add Project 新增專案,並為專案命名。就這次的情況而言,讓我們將專案取名為 ML Kit Introduction。讓專案 ID 保持不變,接著依照情況轉換 Country/region。最後按下 Create Project 按鈕,這應該一分鐘就可以完成。
備註:Firebase 可以創建的專案數量設有上限,所以請謹慎建立專案。

完成後,你的頁面看起來應該像這樣:

這是你的專案總覽頁面,你可以在這控制台操作各種不同的 Firebase 功能。恭喜你,你已經建立了第一個 Firebase 專案!先不要動這個頁面,讓我們來看看 iOS 專案。從這裡下載初始專案。
簡單看看初始專案
打開初始專案,你會看到大部分的 UI 都為你設計好了。建置並執行程式,你會看到一個 UITableView,有不同的 ML Kit 選項並導引到不同的頁面。

如果你點選 Choose Image 按鈕,一個 UIImagePickerView 會彈出,選擇一張圖片就可以改變空佔位符。然而,你選擇了圖片之後卻什麼事都沒發生。到此,我們就需要整合 ML Kit,並在圖片上執行機器學習任務了。
連結 Firebase 到 App
回到你專案的 Firebase 控制台,按下寫著 “Add Firebase to your iOS App” 的按鈕。

然後,應該會有一個窗口彈出,指示你如何連結 Firebase。第一件要做的事,就是連結到你的 iOS Bundle ID,你可以在 Xcode 的專案概覽頁面的 General 頁籤中找到這個 ID。

將 ID 填入欄位,然後按下 Register App。你不需要填寫選填的欄位,因為這個 App 不會上架到 App Store。然後,你會被引導到第二步:下載 GoogleService-Info.plist,這是一個將會加到專案的重要檔案,按 Download 來下載檔案。
如同 Firebase 網站所示,將檔案拖到側邊欄。確認 Copy items if needed 的方格有被勾選。加入了所需的檔案後,你就可以點選 Next 來進行第三步。

使用 Cocoapods 安裝 Firebase 函式庫
下一步我們將介紹 Cocoapods 的概念。Cocoapods 基本上是一個讓你可以簡單地將套件加入專案之中的方法;然而,當中只要有微小的錯誤,就可能導致災難性的結果。首先,關閉所有 Xcode 視窗並退出應用程式。
備註:請確認你是否已經在裝置上安裝 Cocoapods,如果還沒有安裝,這裡有一篇關於 Cocoapods 的教學可以參考,快將它加到你的 Mac 吧。
在你的 Mac 打開終端機,接著輸入以下指令:
cd提示: 要得到 Xcode 專案的路徑,點選 Xcode 專案所在的資料夾,然後按 CMD+C,移到終端機並輸入 cd 然後貼上。
現在我們就在目錄中。

要創建一個 pod 其實相當簡單,輸入以下指令:
pod init等待幾秒鐘之後你的終端機看起來應該像這樣,多加了一行簡單的程式碼。

現在,讓我們加入所有需要的套件到 Podfile。輸入指令到終端機,並等待 Xcode 將它開啟:
open -a Xcode podfile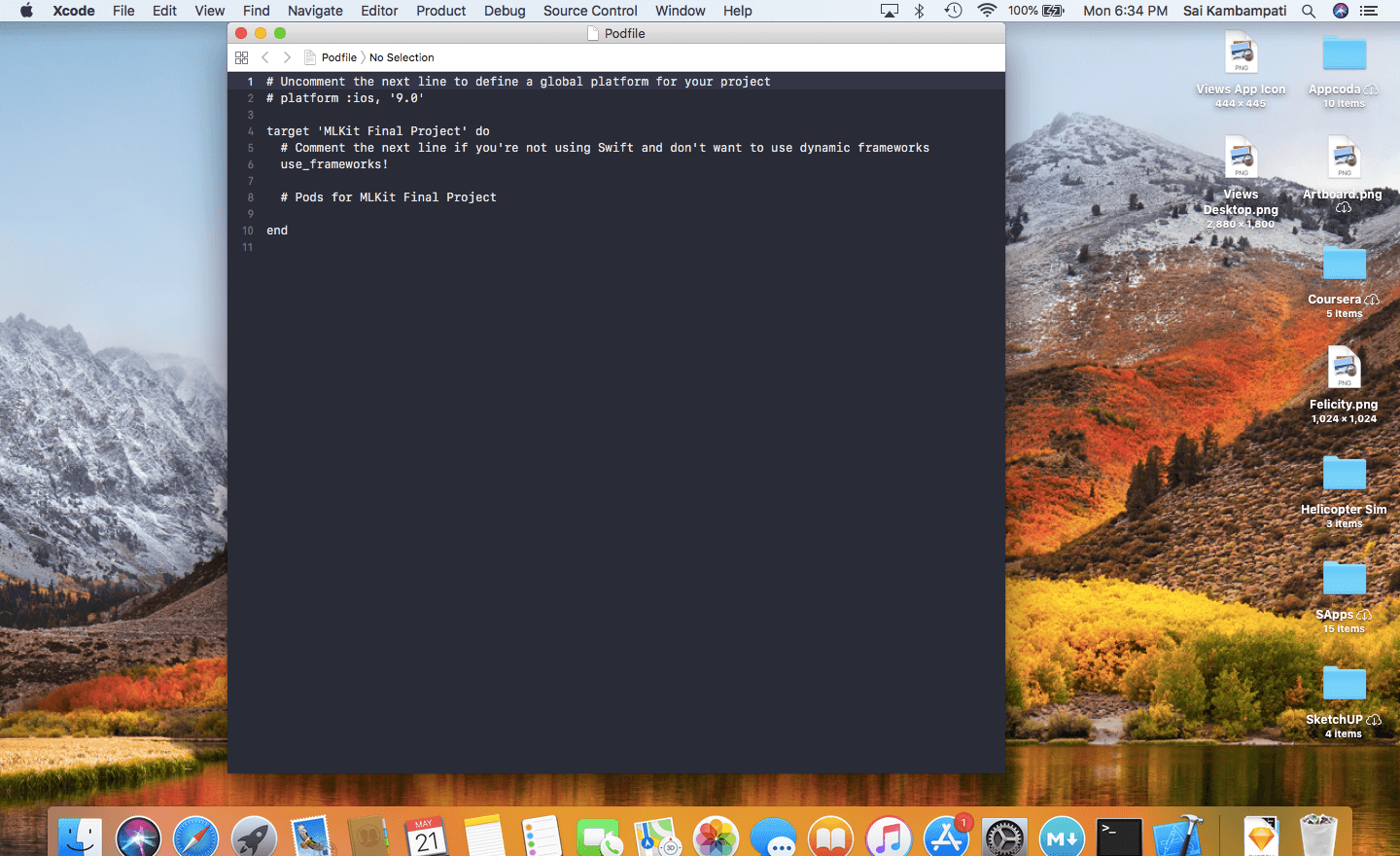
在 # Pods for ML Kit Starter Project 下面輸入下列程式碼:
pod 'Firebase/Core'
pod 'Firebase/MLVision'
pod 'Firebase/MLVisionTextModel'
pod 'Firebase/MLVisionFaceModel'
pod 'Firebase/MLVisionBarcodeModel'
pod 'Firebase/MLVision'
pod 'Firebase/MLVisionLabelModel'你的 Podfile 看起來應該像這樣。

現在,只剩下一件事要做,就是回到終端機並輸入:
pod install這將會花上幾分鐘的時間。與此同時,Xcode 正在下載我們將用到的套件。完成以後,再次回到專案資料夾,你會發現一個新的檔案:一個 .xcworkspace 檔。

這是很多開發者會搞砸的地方:你不應該再次打開 .xcodeproj 檔!如果你在這裡打開檔案並編輯內容,兩個檔案就無法同步,這樣的話你就必須要創建一個新的專案重頭再來。從現在開始,你應該保持 .xcworkspace 檔案打開。
回到 Firebase 的網頁,我們已經完成了第三步,點擊 Next 按鈕來進入第四步。

現在它會要求我們打開工作區,並加入幾行程式碼到我們的 AppDelegate.swift 檔。打開 .xcworkspace 檔(再次提醒,不是 .xcodeproj 檔,這一點非常重要),然後切換到 AppDelegate.swift 檔。
當我們在 AppDelegate.swift 檢視頁面之中,唯一需要做的就是加入兩行程式碼。
import UIKit
import Firebase
@UIApplicationMain
class AppDelegate: UIResponder, UIApplicationDelegate {
var window: UIWindow?
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplicationLaunchOptionsKey: Any]?) -> Bool {
// Override point for customization after application launch.
FirebaseApp.configure()
return true
}我們這裡做的是加入 Firebase 套件,並根據之前的 GoogleService-Info.plist 檔來設置它。你可能會得到一個錯誤訊息,顯示它無法建置 Firebase 模組,不過只要按下 CMD+SHFT+K 來清除專案,再按 CMD+B 即可建置它。

如果錯誤依然存在,切換到專案的 Build Settings 頁籤,搜尋 Bitcode。你會在 Build Options 下面看到 Enable Bitcode 的選項,將它設定為 No 並再次建置,就應該會成功了。

在 Firebase 控制台按 Next 按鈕來到第五步。現在,你所需要做的就是在裝置上執行 App,第五步就會自動完成了!你應該會被重新導向到專案的概覽頁面,你現在可以在那裡看到一些數據項目。

恭喜你,你已經完成了本教學中最具挑戰性的部分!現在就只需要在 Swift 中加入 ML Kit 程式碼。這是完美的休息時間,從這裡開始,我們就只是在熟悉的程式碼中漫遊!
條碼掃描
第一個實作的功能就是條碼掃描,要把它加到 App 中真的非常簡單。切換到 BarcodeViewController,你會看到當 Choose Image 按鈕按下時出現的程式碼。為了獲得所有 ML Kit 協定,我們需要加入 Firebase。
import UIKit
import Firebase接著我們需要定義一些在條碼掃描功能中會使用到的變數。
let options = VisionBarcodeDetectorOptions(formats: .all)
lazy var vision = Vision.vision()options 變數會告訴 BarcodeDetector 要辨識的條碼類型,ML Kit 可以辨識大部分常見的條碼格式,像是 Codabar、Code 39、Code 93、UPC-A、UPC-E、Aztec、PDF417、QR Code 等。針對我們的目的,我們會要求檢測器辨識所有類型的格式。vision 變數回傳 Firebase Vision 服務的實例,我們就是透過這個變數來執行大部分的計算。

接下來,我們需要處理辨識的邏輯,我們將會在 imagePickerController:didFinishPickingMediaWithInfo 函數內實現這部分,這個函數會在我們選取圖像後執行。現在,函數只會將 imageView 設定成我們所選取的圖像。在 imageView.image = pickedImage 底下加入下列程式碼。
// 1
let barcodeDetector = vision.barcodeDetector(options: options)
let visionImage = VisionImage(image: pickedImage)
//2
barcodeDetector.detect(in: visionImage) { (barcodes, error) in
//3
guard error == nil, let barcodes = barcodes, !barcodes.isEmpty else {
self.dismiss(animated: true, completion: nil)
self.resultView.text = "No Barcode Detected"
return
}
//4
for barcode in barcodes {
let rawValue = barcode.rawValue!
let valueType = barcode.valueType
//5
switch valueType {
case .URL:
self.resultView.text = "URL: \(rawValue)"
case .phone:
self.resultView.text = "Phone number: \(rawValue)"
default:
self.resultView.text = rawValue
}
}
}讓我們簡單看看程式碼所做的事。雖然程式碼看起來很多但其實很簡單,而且這將會是本教學其餘部分的基本格式。
- 我們做的第一件事是定義兩個變數,第一個是
barcodeDetector,一個 Firebase Vision 服務的條碼掃描物件,我們將其設定為辨識所有條碼格式。接著定義一張稱為visionImage的圖像,跟我們所選取的圖像一致。 - 呼叫
barcodeDetector的detect方法,並對我們的visionImage執行此方法。我們定義了兩個物件:barcodes以及error。 - 首先,我們來處理錯誤。如果發生了錯誤或是無法辨識到條碼,就要關閉 Image Picker View Controller,並設定
resultView為 “No Barcode Detected”。然後return這個函數讓剩餘的部分無法被執行。 - 如果有條碼被辨識到,我們就使用一個 for-loop 來對每一個辨識到的條碼執行相同程式碼。我們定義了兩個常數:一個
rawValue以及一個valueType。條碼的 Raw Value 包含了其保存的數據,可能是一些文字、數字或圖像等;而條碼的 Value type 就說明了訊息的類型:電子郵件、聯絡人或連結等。 - 現在我們可以簡單印出原始數值,但這並不會提供很好的使用者體驗;相反地,我們將依據 Value type 來提供客制化訊息。我們確認條碼類型後,並將
resultView的文字設定為相對應的類型。舉例來說,如果是 URL 的話,我們將resultView的文字設為 “URL: “,然後顯示該 URL。
建置並執行 App,它應該運作得非常快!最酷的是,由於 resultView 是一個 UITextView,你可以跟它互動、並選擇任何被偵測到的數據如數字、連結和電子郵件等。

臉部偵測
接下來,我們來看一下臉部偵測的應用。與以往只在圖像上框出臉部範圍不同,讓我們進一步看看要怎麼辨認人物是否正在微笑、眼睛是否有睜開等。
就像剛剛一樣,我們需要從定義一些常數開始。
import UIKit
import Firebase
.
.
.
let options = VisionFaceDetectorOptions()
lazy var vision = Vision.vision()與先前的程式碼唯一不同的地方,是我們呼叫了 FaceDetectorOptions 的預設值,然後在類別的 viewDidLoad 之中設置了這些選項。
override func viewDidLoad() {
super.viewDidLoad()
imagePicker.delegate = self
// Do any additional setup after loading the view.
options.modeType = .accurate
options.landmarkType = .all
options.classificationType = .all
options.minFaceSize = CGFloat(0.1)
}我們在viewDidLoad之中定義了偵測器的細節。首先,我們選擇了使用的模式,模式有 accurate 與 fast 兩種。因為這只是一個範例 App,我們將選擇 accurate 模式。但是如果在某些速度較重要的情況下,調用 options.modeType = .fast 可能是更明智的選擇。
下一步我們要求偵測器找到所有的標誌及分類的情況。這兩點有什麼不同?標誌是指臉部的特定部位,像是右臉頰、左臉頰、鼻子底部、眉毛和其他部位等;而分類會是偵測某些事件,就目前的情況而言,ML Kit Vision 只能夠偵測左或右眼是否已經睜開,以及人物是否在微笑。針對我們的目的,要處理的就只有微笑和睜開眼與否的分類。
最後一個需要設定的選項是臉部最小尺寸,當我們輸入 options.minFaceSize = CGFloat(0.1) 就代表想偵測臉部的最小尺寸。這尺寸是用臉部寬度和圖片寬度的比例來表示,如果數值是 0.1,就代表我們指示偵測器搜尋最小尺寸不低於圖像寬度 10% 的臉部。

接著,讓我們來處理一下 imagePickerController:didFinishPickingMediaWithInfo 方法中的邏輯,在 imageView.image = pickedImage 一行下輸入下列程式碼:
let faceDetector = vision.faceDetector(options: options)
let visionImage = VisionImage(image: pickedImage)
self.resultView.text = ""這簡單地以剛剛定義的選項設定 ML Kit Vision 服務為臉部偵測器,我們也定義了 visionImage 為所選擇的圖片。因為這部分的程式可能會重複執行,所以我們會想清除 resultView,第三行程式碼就是用來清除它的。接下來,呼叫 faceDetector 的偵測函數。
//1
faceDetector.detect(in: visionImage) { (faces, error) in
//2
guard error == nil, let faces = faces, !faces.isEmpty else {
self.dismiss(animated: true, completion: nil)
self.resultView.text = "No Face Detected"
return
}
//3
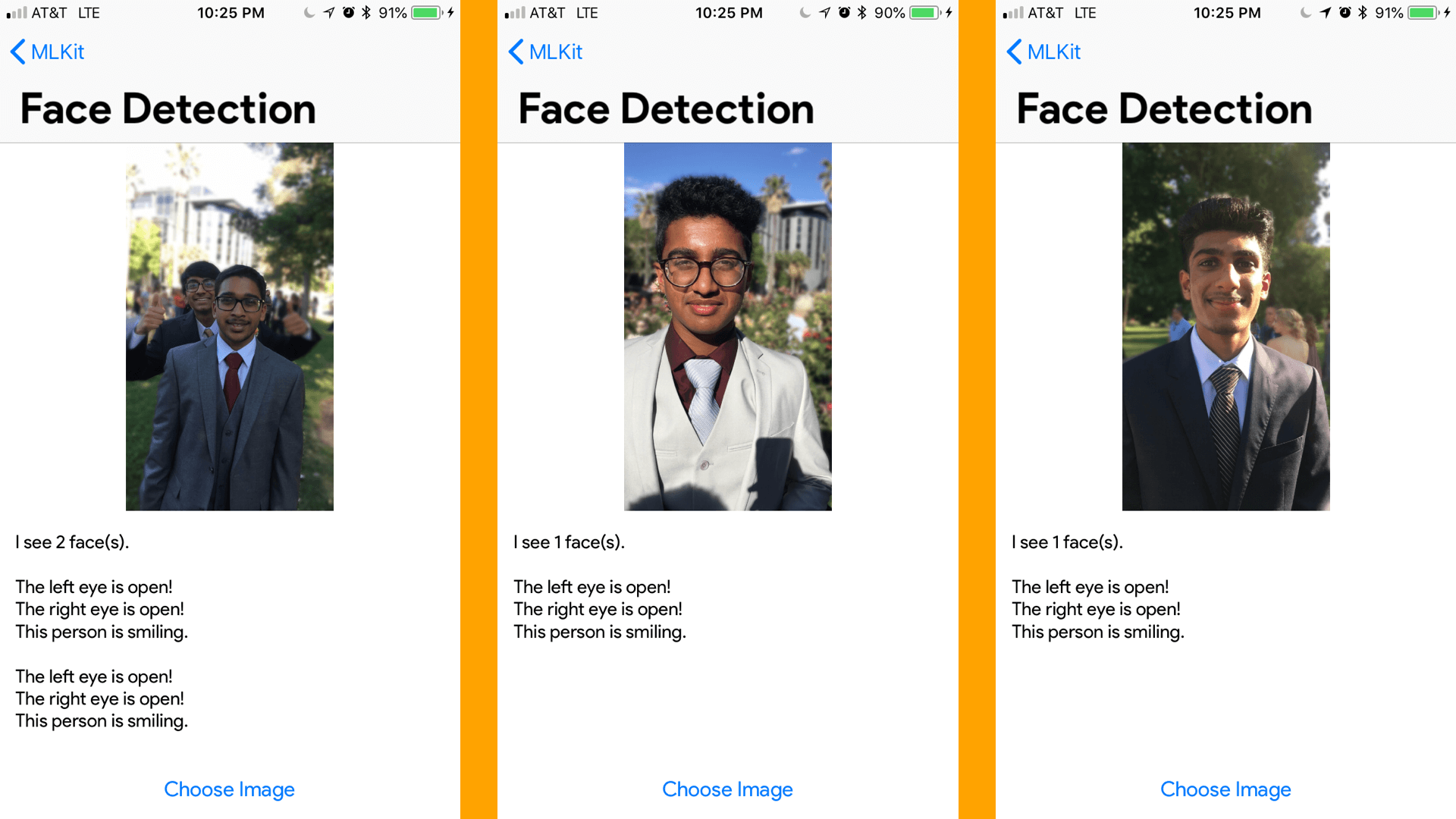
self.resultView.text = self.resultView.text + "I see \(faces.count) face(s).\n\n"
for face in faces {
//4
if face.hasLeftEyeOpenProbability {
if face.leftEyeOpenProbability < 0.4 {
self.resultView.text = self.resultView.text + "The left eye is not open!\n"
} else {
self.resultView.text = self.resultView.text + "The left eye is open!\n"
}
}
if face.hasRightEyeOpenProbability {
if face.rightEyeOpenProbability < 0.4 {
self.resultView.text = self.resultView.text + "The right eye is not open!\n"
} else {
self.resultView.text = self.resultView.text + "The right eye is open!\n"
}
}
//5
if face.hasSmilingProbability {
if face.smilingProbability < 0.3 {
self.resultView.text = self.resultView.text + "This person is not smiling.\n\n"
} else {
self.resultView.text = self.resultView.text + "This person is smiling.\n\n"
}
}
}
}這與剛剛的條碼偵測函數應該非常相似,讓我們來看看程式碼所做的事:
- 呼叫
visionImage的偵測函數來找尋faces和errors。 - 若有錯誤情況或未有偵測到臉部,就將
resultView文字設為 "No Face Detected" 並回傳方法。 - 若成功偵測到臉部,我們所印的
resultView第一句文字敘述就會顯示偵測到多少張臉。教學內的字串中,你會常常看到許多\n符號,代表換行的意思。 - 更進一步觀察細節,如果
face的左眼有可能睜開了,我們就檢查該機率實際為多少。就這個情況而言,如果機率小於 0.4,我就認定左眼是閉合的,右眼也是如此。當然你可以設置為任何想要的值。 - 同樣地,我會確認微笑的機率,如果機率小於 0.3,這個人很可能就沒有在微笑;反之就是有在微笑。
備註:這些數值是依據個人感覺選擇的,因為微笑比睜開眼睛較難被察覺,所以我降低了它對應的機率值,這樣它就更有可能做出正確的推論。
建置並執行你的程式,看看運作的結果。你可以任意調整的機率值來玩玩看會有什麼結果!
圖像標籤
接著,我們會開始進行圖像標籤的部分,這比臉部偵測簡單得多。實際上,在圖像標籤和文字辨識上,你可以有兩種選擇,一是在你的設備上完成所有機器學習的任務(這是 Apple 喜歡的方式,因為所有數據都屬於用戶,這樣可以就離線運作,又不會對 Firebase 做任何呼叫);二是你可以使用 Google 的 Cloud Vision。使用 Cloud Vision 的好處是模型會自動更新而且更準確,因為比起在設備上,Cloud Vision 在雲端上很容易就可以有更大更準確的模型規模。不過,針對我們的目的,我們延續剛剛所做的一切,只實現設備上的版本就好。
看看你能不能獨自完成它吧,這跟前兩個的情況非常類似,真的不行的話也沒關係。以下就是我們要做的事!
import UIKit
import Firebase
...
lazy var vision = Vision.vision()跟剛剛不同的是,我們的標籤偵測器將使用預設設定,因此只需要定義一個常數。與前文一樣,在 imagePickerController:didFinishPickingMediaWithInfo 方法之中,imageView.image = pickedImage 這行底下輸入下列程式碼:
//1
let labelDetector = vision.labelDetector()
let visionImage = VisionImage(image: pickedImage)
self.resultView.text = ""
//2
labelDetector.detect(in: visionImage) { (labels, error) in
//3
guard error == nil, let labels = labels, !labels.isEmpty else {
self.resultView.text = "Could not label this image"
self.dismiss(animated: true, completion: nil)
return
}
//4
for label in labels {
self.resultView.text = self.resultView.text + "\(label.label) - \(label.confidence * 100.0)%\n"
}
}這看起來應該非常熟悉,讓我簡單解釋一下:
- 我們定義
labelDetector來告訴 ML Kit 的 Vision 服務,以偵測圖像的標籤。定義visionImage為我們所選的圖像。若要重複使用此函數,清除resultView。 - 我們呼叫了
visionImage的detect函數,並找尋labels和errors。 - 如果 ML Kit 發生錯誤,或是無法標籤圖像,就回傳函數,並告訴使用者我們無法標籤圖像。
- 如果運作正常,那就將
resultView的文字設定為圖像的標籤,以及 ML Kit 標籤這張圖時有多少信心。
很簡單對吧?建構並執行你的程式碼!看一下標籤有多準確(或瘋狂)?

文字辨識
我們幾乎完成了!光學字元辨識 (Optical Character Recognition,OCR) 過去兩年成為了行動裝置 App 最熱門的的術語。有了 ML Kit,要將文字辨識功能實現在你的程式之中就更加容易了,讓我們看看怎麼做吧!
此外,文字辨識功能可以連接到 Google Cloud,並可以通過雲端模式呼叫模型,就像圖片標籤功能一樣,但我們現在將使用設備上的 API 來實作。
import UIKit
import Firebase
...
lazy var vision = Vision.vision()
var textDetector: VisionTextDetector?跟剛剛一樣,我們呼叫 Vision 服務並定義一個 textDetector,我們可以在 viewDidLoad 方法中設定 textDetector 變數為 vision 的文字偵測器。
override func viewDidLoad() {
super.viewDidLoad()
imagePicker.delegate = self
textDetector = vision.textDetector()
}接著,我們只需要處理 imagePickerController:didFinishPickingMediaWithInfo 中的部分。如同往常一樣,我們在 imageView.image = pickedImage 這行下面輸入處理相關邏輯的程式碼。
//1
let visionImage = VisionImage(image: pickedImage)
textDetector?.detect(in: visionImage, completion: { (features, error) in
//2
guard error == nil, let features = features, !features.isEmpty else {
self.resultView.text = "Could not recognize any text"
self.dismiss(animated: true, completion: nil)
return
}
//3
self.resultView.text = "Detected Text Has \(features.count) Blocks:\n\n"
for block in features {
//4
self.resultView.text = self.resultView.text + "\(block.text)\n\n"
}
})- 我們設定
visionImage為我們選擇的圖像,並為圖像執行detect函數來找尋features和errors。 - 如果發生錯誤或是沒有偵測到文字,就告訴使用者 "Could not recognize any text" 然後回傳函數。
- 我們給使用者的第一個資訊,是總共有幾段文字被偵測到。
- 最後,我們將
resultView的文字設為每個區塊的文字,並在\n\n之間留出空格(新的兩行)。
測試一下!嘗試使用不同的字體和顏色,我的結果顯示,它的功能對於印刷文字的辨識完美無瑕,但辨識手寫文字的確很困難。

地標辨識
地標辨識可以像其他 4 個類型一樣如法炮製。不幸的是,ML Kit 目前不支援在設備上進行地標辨識。 若要執行地標辨識,你需要將專案項目更改為 "Blaze",並激活 Google Cloud Vision API。

不過,這已經超出了本教學涵蓋的範圍,如果你想要自我挑戰的話,可以參考這份文件來實作,程式碼也包含在最後的專案內!
結論
這篇教學內容真的很豐富,請隨時回來重新查閱不熟悉的部分。如果有任何文章未有解答的問題,歡迎在下面發表評論!藉由 ML Kit,你可以看到在 App 中實現智慧機器學習功能是多麼容易,可以創造的 App 範圍很廣,以下是一些你可以嘗試的想法:
- 辨識文字並向視障使用者朗讀內容的 App。
- 類似 Try Not to Smile by Roland Horvath 的人臉追蹤 App
- 條碼偵測器
- 以標籤來搜尋圖片
這些想法是無盡的,取決於你的想像力,以及想如何幫助使用者。你可以在這裡下載最終的專案。如果你想了解更多有關 ML Kit API 的資料,可以查看他們的文件。希望你在本教學中學到新的東西,並留言和我分享你的進度!
你可以到 GitHub 下載完整專案。




